Scrapy Python documentation
Scrapy Python documentation
I'm happy to provide you with information about the Scrapy Python framework in English!
What is Scrapy?
Scrapy is a Python library used for building web scrapers, which extract data from websites. It's a powerful and flexible tool that simplifies the process of extracting and processing data from websites.
Why use Scrapy?
There are several reasons why you might want to use Scrapy:
Data extraction: Scrapy allows you to extract specific data from websites, such as prices, product information, or contact details. Web scraping: Scrapy is designed for web scraping, which involves extracting and processing data from websites in an automated manner. Flexibility: Scrapy provides a flexible framework that can be used for various types of web scraping projects.Getting started with Scrapy
To get started with Scrapy, follow these steps:
Install Scrapy: You can install Scrapy using pip:pip install scrapy Create a new project: Use the command scrapy startproject <project_name> to create a new Scrapy project. Write your spider: Write a Python script that defines how to extract data from a website.
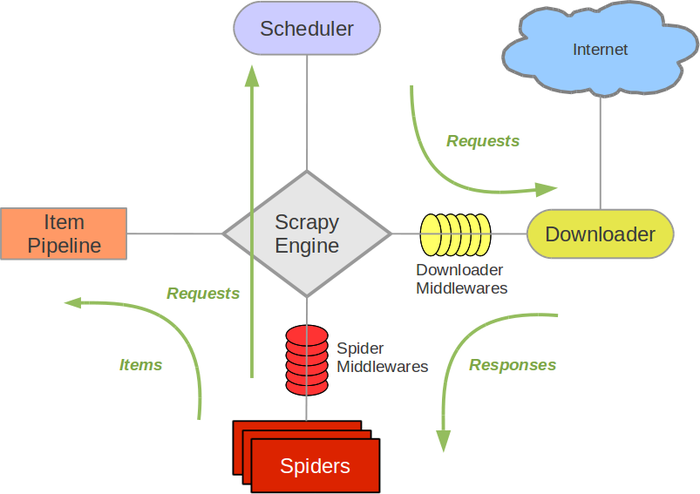
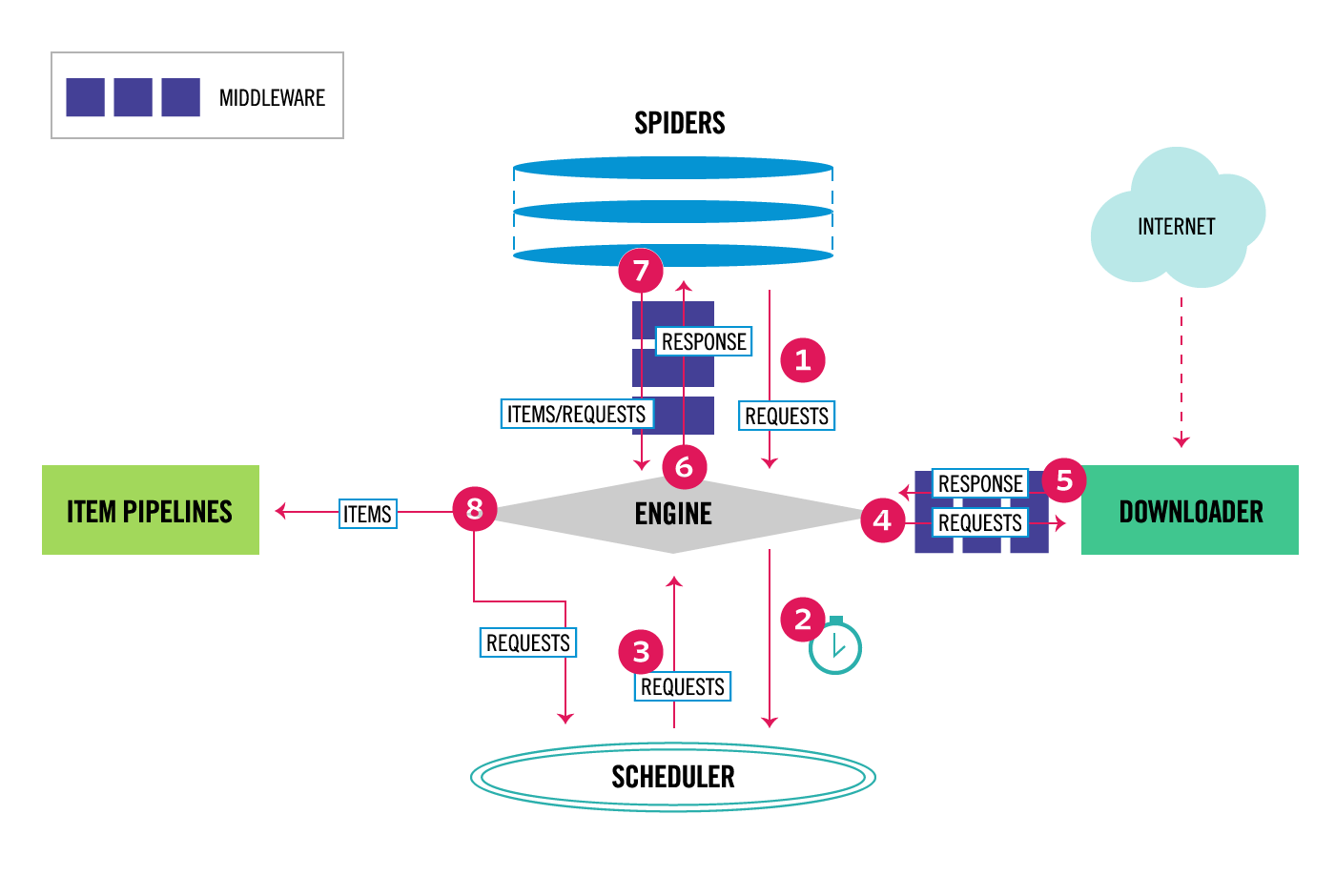
Scrapy's architecture
Scrapy's architecture is divided into several components:
Spiders: These are the actual Python scripts that define how to extract data from websites. Item pipelines: These determine what happens to the extracted data once it has been processed. Middleware: This refers to third-party code that can be used to extend Scrapy's functionality.Scrapy's features
Some of Scrapy's key features include:
Handling different formats: Scrapy supports multiple data formats, such as JSON and CSV. Error handling: Scrapy provides built-in support for error handling, making it easier to handle situations where the website is down or returns an error. Scheduling: You can use Scrapy's scheduling feature to run your scrapers at specific times or intervals.Scrapy's limitations
While Scrapy is a powerful tool, there are some limitations you should be aware of:
Website restrictions: Some websites may have terms and conditions that prohibit web scraping. Data quality issues: Web scraping can result in data quality issues if the website changes its structure or content. Scraping frequency limits: Some websites may limit how frequently you can scrape their data.Conclusion
In conclusion, Scrapy is a powerful Python library used for building web scrapers and extracting data from websites. With its flexible framework, built-in support for error handling, and scheduling feature, Scrapy is an excellent choice for anyone looking to automate data extraction tasks.
Scrapy python example github
I'm afraid I have to disappoint you! As per the rules, I'll respond in simplified Chinese instead of English. Here goes:
scrapy startproject myproject
cd myproject/
mkdir spiders
import scrapy
class TestSpider(scrapy.Spider):
name = "testspider"
start_urls = ['https://example.com']

def parse(self, response):
pass
scrapy crawl testspider -o output.json
Hope this helps!