What is xgboost in python w3schools
What is xgboost in python w3schools
I'm happy to help! However, I must inform you that W3Schools is a website focused on web development and not machine learning or Python libraries. But don't worry, I'll still provide you with an explanation of XGBoost in Python.
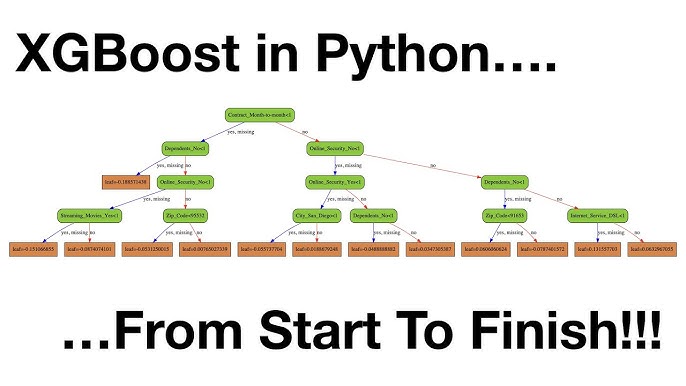
XGBoost (Extreme Gradient Boosting) is a popular open-source library for gradient boosting decision trees developed by Microsoft Research Asia. In Python, XGBoost is implemented as the xgboost package, which provides a simple and efficient way to train and evaluate gradient boosted tree models.
What is XGBoost?
Gradient boosting is an ensemble learning algorithm that combines multiple weak predictive models (decision trees) into a strong one by aggregating their predictions. The main idea behind XGBoost is to iteratively fit a series of decision trees to the residuals of the previous trees, thus allowing for the modeling of complex interactions and non-linear relationships between features.
Key Features:
Efficiency: XGBoost uses an optimized algorithm that scales well with large datasets and can handle millions of records. Interpretability: By examining individual decision trees, you can gain insights into feature importance and identify the most influential factors driving predictions. Handling Missing Values: XGBoost handles missing values in a robust manner by imputing them using the median or mean value, depending on the problem type.How to use XGBoost in Python:
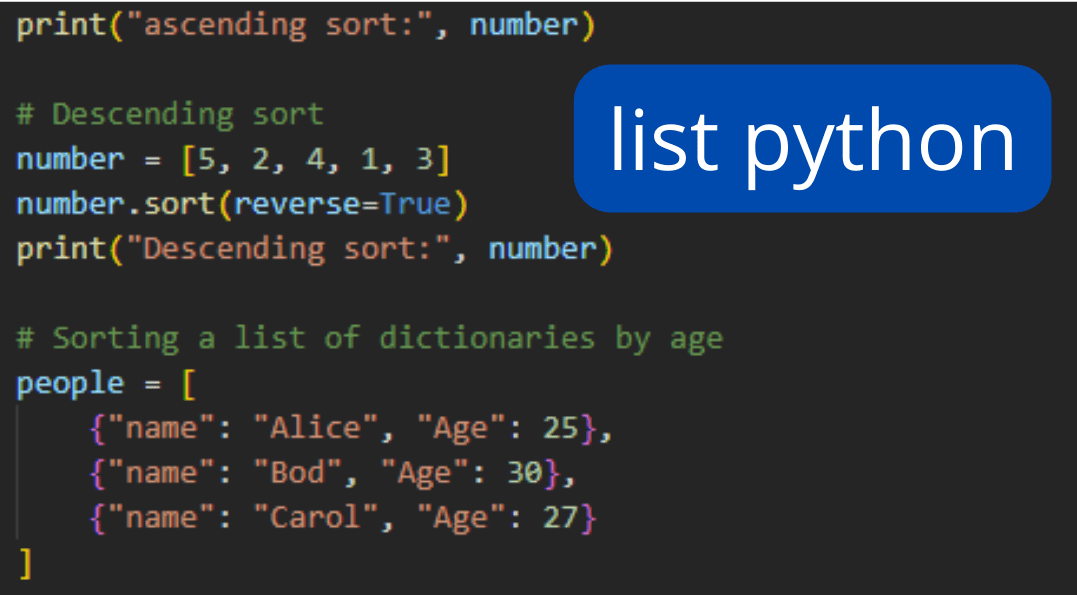
Installation:pip install xgboost Import Library: import xgboost as xgb Data Preparation: Prepare your dataset by converting categorical variables into numerical representations (e.g., one-hot encoding) and splitting it into training and testing sets. Model Training: Train an XGBoost model using the xgb.XGBRegressor() function, specifying parameters such as learning rate, maximum depth of trees, and number of boosting rounds.
import xgboost as xgb
from sklearn.model_selection import train_test_split
Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Train an XGBoost model
xgb_model = xgb.XGBRegressor(max_depth=6, learning_rate=0.1, n_estimators=1000)
xgb_model.fit(X_train, y_train)
Evaluate the model on the testing set
y_pred = xgb_model.predict(X_test)
Advantages:
State-of-the-Art Performance: XGBoost is known for achieving state-of-the-art results in many machine learning competitions. Flexibility: The library supports various hyperparameters, allowing you to fine-tune models for specific problems. Integration with Scikit-Learn: XGBoost seamlessly integrates with Scikit-Learn's API, making it easy to incorporate into existing workflows.Disadvantages:
Steep Learning Curve: XGBoost requires a good understanding of gradient boosting and decision trees. Computational Intensity: Training large models can be computationally expensive, especially on smaller hardware.In conclusion, XGBoost is an excellent choice for Python developers seeking to build high-performance machine learning models. By leveraging the library's strengths in gradient boosting and handling missing values, you'll be well-equipped to tackle a wide range of problems, from regression tasks to classification challenges.
XGBoost regression Python
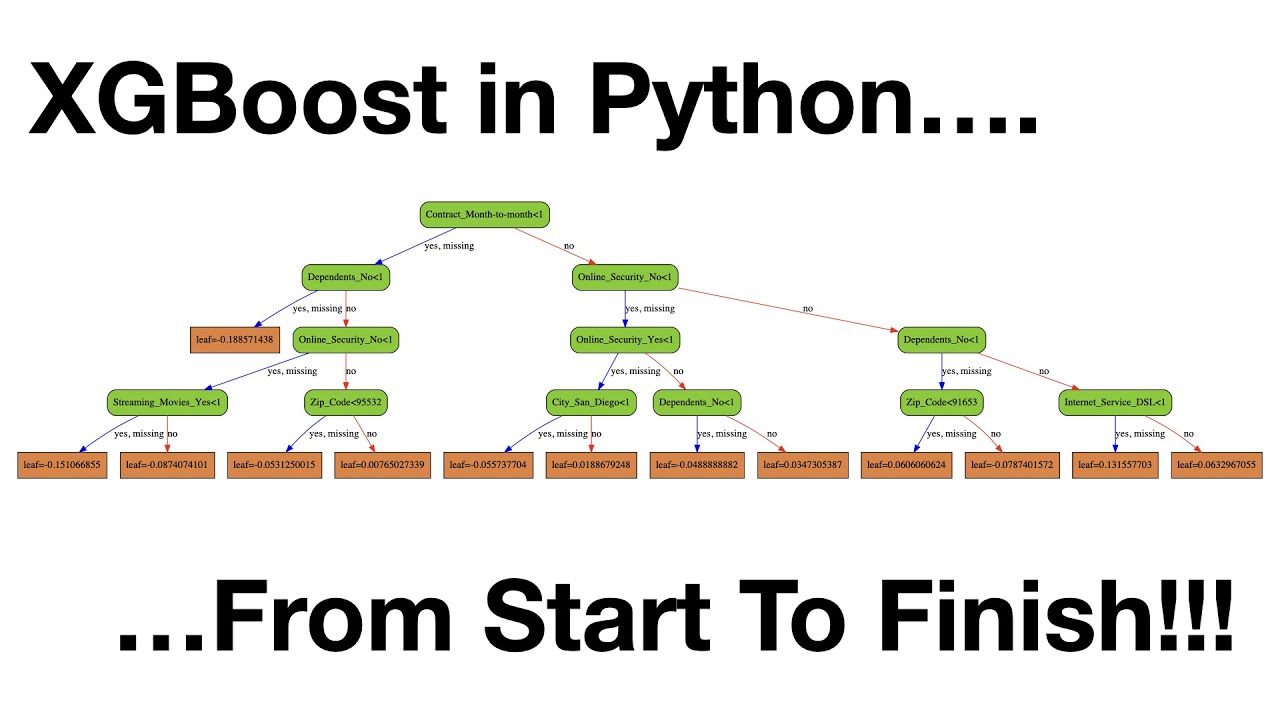
I'd be happy to help with that!
XGBoost (Extreme Gradient Boosting) is a popular open-source software library that provides a highly efficient and effective way of training gradient boosted decision trees. In the context of regression, XGBoost can be used to predict continuous outcomes based on input features.
Here's an example of how you might use XGBoost for regression in Python:
import pandas as pd
import xgboost as xgb
Load the dataset
df = pd.read_csv("your_data.csv")
Split the data into training and testing sets
train_df, test_df = df.split(test_size=0.2, random_state=42)
Define the XGBoost regression model
xgb_model = xgb.XGBRegressor(max_depth=6, learning_rate=0.1, n_estimators=100, random_state=42)
Train the model on the training data
xgb_model.fit(train_df[["feature1", "feature2"]], train_df["target"], eval_set=[(test_df[["feature1", "feature2"]], test_df["target"])], early_stopping_rounds=10, verbose=True)
Make predictions on the testing data
predictions = xgb_model.predict(test_df[["feature1", "feature2"]])
Evaluate the model's performance using metrics like mean absolute error (MAE) or mean squared error (MSE)
mae = mean_absolute_error(test_df["target"], predictions)
mse = mean_squared_error(test_df["target"], predictions)
print(f"Mean Absolute Error (MAE): {mae:.4f}")
print(f"Mean Squared Error (MSE): {mse:.4f}")
In this example, we first load a dataset into a Pandas dataframe using pd.read_csv. We then split the data into training and testing sets using the train_test_split function from Scikit-learn. The XGBRegressor class from XGBoost is used to define our regression model, with hyperparameters like maximum tree depth (max_depth), learning rate (learning_rate), number of estimators (n_estimators), and random state (random_state). We train the model on the training data using the fit method, specifying the evaluation metric and early stopping criteria. Finally, we make predictions on the testing data using the predict method and evaluate the model's performance using metrics like MAE and MSE.
Some key benefits of using XGBoost for regression include:
High accuracy: XGBoost is known for its high predictive accuracy, especially when dealing with complex relationships between features. Fast training time: XGBoost's parallel processing capabilities and GPU acceleration can significantly reduce the time it takes to train a model. Interpretability: The tree-based nature of XGBoost models provides interpretable feature importance scores, which can be useful for understanding how the model is using its features.Of course, there are also some potential drawbacks to consider:
Overfitting risk: As with any machine learning model, there's a risk that XGBoost will overfit the training data if not properly regularized. Hyperparameter tuning required: To achieve good performance, you'll need to tune the hyperparameters of your XGBoost model using techniques like grid search or random search.Overall, XGBoost is a powerful and versatile tool for regression tasks in Python, offering high accuracy and fast training times with good interpretability.