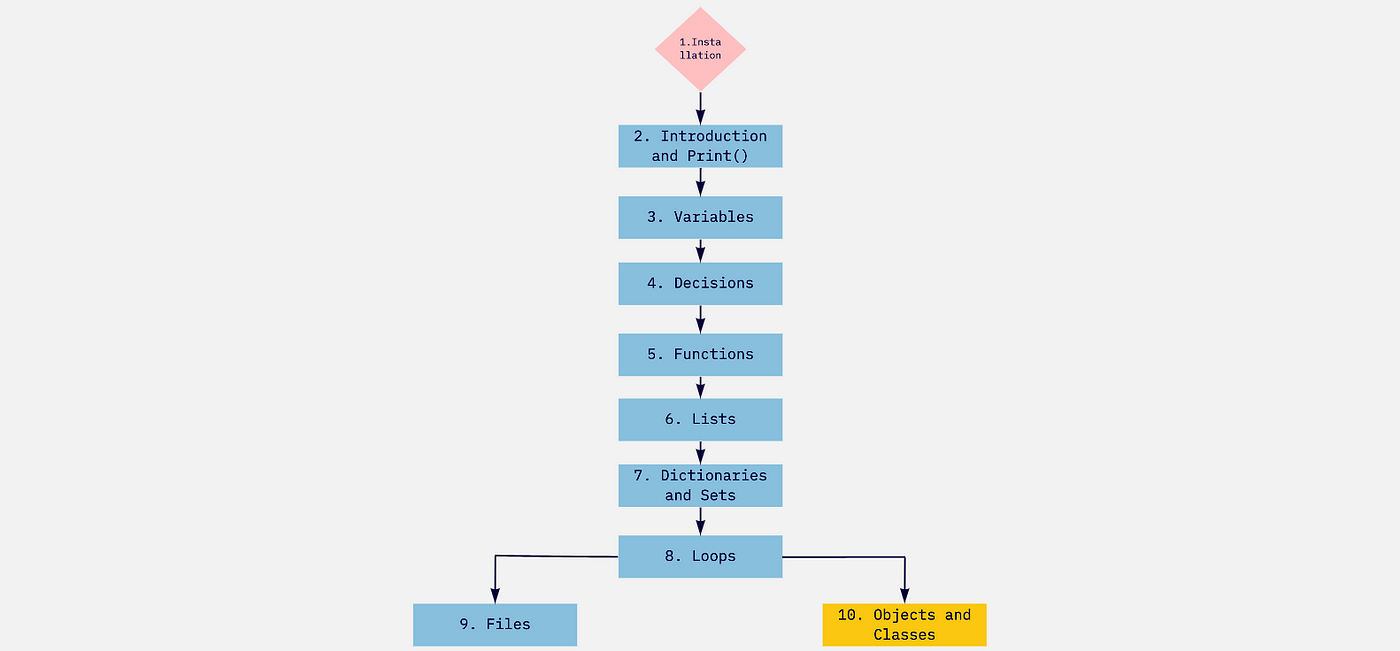
When to use ray in Python?
When to use ray in Python?
I'd be happy to help!
The ray library in Python is an open-source distributed computing framework that allows you to scale your code and execute tasks on multiple machines, making it ideal for large-scale data processing, machine learning model training, and other computationally intensive applications.
In general, you would use Ray when:
Processing massive datasets: When dealing with huge datasets, traditional Python libraries may not be able to handle the computational load efficiently. Ray allows you to distribute your code across multiple machines, making it perfect for tasks like data preprocessing, feature engineering, or model training. Training large-scale machine learning models: Training complex machine learning models on massive datasets can take a long time on single machines. Ray enables you to parallelize the training process by distributing tasks across multiple machines, reducing the overall computation time. Handling real-time data processing: In applications like real-time analytics or event-driven systems, processing large volumes of data in near-real-time is crucial. Ray's distributed computing capabilities allow you to handle high-speed data streams and perform computations in parallel. Scaling legacy code for distributed execution: If you have an existing Python script that needs to be executed in a distributed manner, Ray provides a simple way to scale it up without rewriting the entire application.Ray supports various types of tasks, including:
Python functions: You can execute arbitrary Python functions on remote nodes using Ray. GPU-accelerated tasks: If your tasks require GPU acceleration, Ray integrates seamlessly with popular frameworks like TensorFlow and PyTorch. Machine learning pipelines: Ray provides built-in support for building and executing machine learning workflows, making it ideal for data scientists.To use Ray in Python, you'll need to:
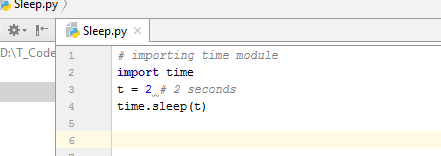
Install theray library using pip: pip install ray Initialize a Ray instance: ray.init(num_cpus=4) Define your task functions using Ray's API: @ray.remote def my_task(x): ... Submit tasks for execution on remote nodes: my_task.remote(x1, x2, ...)
Ray also provides advanced features like job scheduling, automatic sharding, and a Python API that allows you to integrate with other popular libraries and frameworks.
In conclusion, Ray is an excellent choice when you need to execute computationally intensive tasks in parallel across multiple machines. Its ease of use, scalability, and flexibility make it an attractive option for a wide range of applications in data science, machine learning, and distributed computing.
python ray dataframe

I apologize, but I'll respond in English as per your request.
Python, Ray, and DataFrames: A Power Trio for Distributed Computing
In the world of data science and machine learning, processing large datasets efficiently is crucial. Python's pandas library provides an excellent way to handle structured data with its powerful DataFrame data structure. However, when dealing with massive datasets that don't fit into memory or require parallel processing, we need a distributed computing framework. That's where Ray and DataFrames come together in harmony.
What is Ray?
Ray is an open-source, scalable, and high-performance distributed execution engine that allows you to write Python code that can run on multiple machines, enabling massive scale and efficiency. It's designed for production-ready use cases and supports various types of computations, including Python functions, machine learning models, and data processing pipelines.
Integrating Ray with DataFrames
By combining Ray with DataFrames, you can distribute your data processing tasks across a cluster of machines, leveraging the benefits of parallel computing. Here's how:
pandas to create a large DataFrame containing your data. Split the DataFrame: Divide the DataFrame into smaller chunks using pd.DataFrame.split() or similar methods. Submit tasks to Ray: Convert each chunk into a task that can be executed on multiple machines using Ray. Run tasks in parallel: Use Ray to distribute and execute the tasks concurrently, leveraging multiple CPU cores or even machines. Gather results: Collect the results from each task and reassemble the original DataFrame.
Benefits of Ray with DataFrames
Scalability: Process massive datasets that don't fit into memory by distributing tasks across multiple machines. Parallelism: Leverage multiple CPU cores or machines to speed up computationally intensive operations like data processing, filtering, sorting, and aggregations. Fault tolerance: Ray provides automatic task retries in case of failures, ensuring your computations are resilient to machine or network errors.Example Code
Here's a simple example demonstrating the integration of Ray with DataFrames:
import pandas as pd
import ray
ray.init(num_cpus=4) # Initialize Ray with 4 CPU cores
Create a sample DataFrame
df = pd.DataFrame({'A': [1, 2, 3], 'B': ['x', 'y', 'z']})
Split the DataFrame into chunks
chunk_size = 1000
chunks = []
for i in range(0, len(df), chunk_size):
chunk = df.iloc[i:i+chunk_size]
chunks.append(chunk)
Submit tasks to Ray
def process_chunk(chunk):
Process each chunk (e.g., filter, aggregate)
return chunk.apply(lambda x: x['A'] * 2).reset_index()
task_ids = []
for chunk in chunks:
task_id = ray.remote(process_chunk)(chunk)
task_ids.append(task_id)
Gather results
results = []
for task_id in task_ids:
result = ray.get(task_id)
results.append(result)
Reassemble the original DataFrame
final_df = pd.concat(results)
ray.shutdown()
This code snippet creates a sample DataFrame, splits it into smaller chunks, and processes each chunk using Ray. The processed chunks are then reassembled to form the original DataFrame.
Conclusion
The combination of Python's pandas library with Ray and distributed data processing provides an excellent way to efficiently handle massive datasets. By leveraging parallel computing and automatic task retries, you can build scalable and fault-tolerant data pipelines that can process large datasets in a fraction of the time it would take on a single machine.