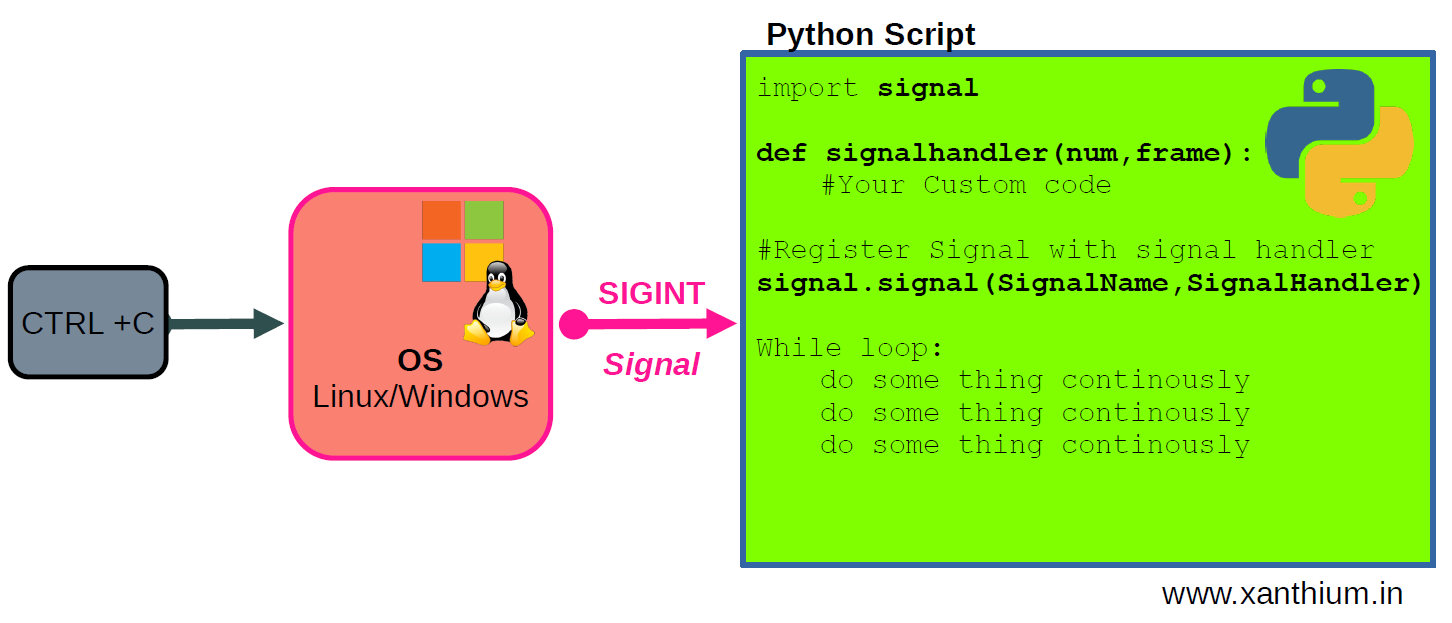
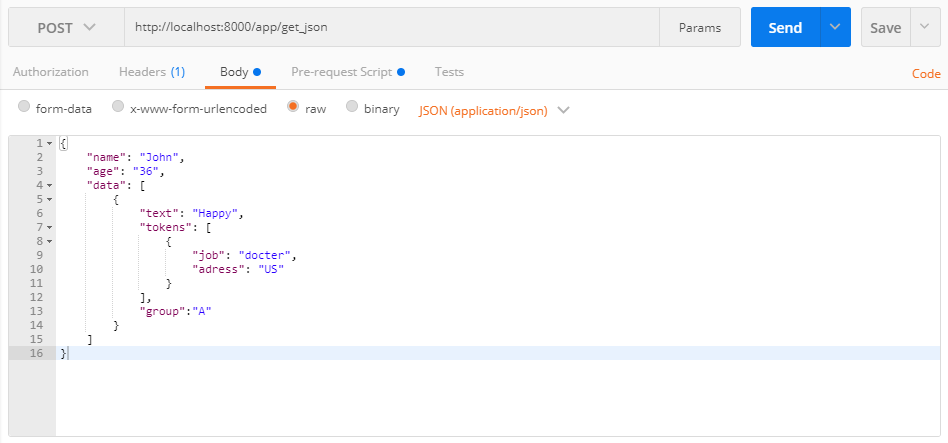
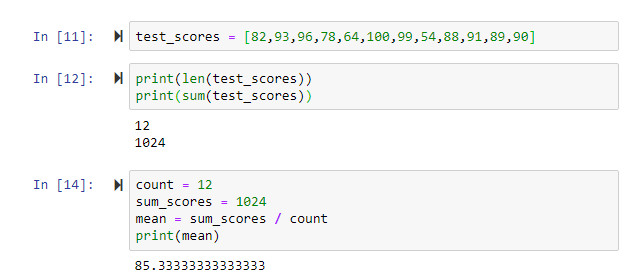
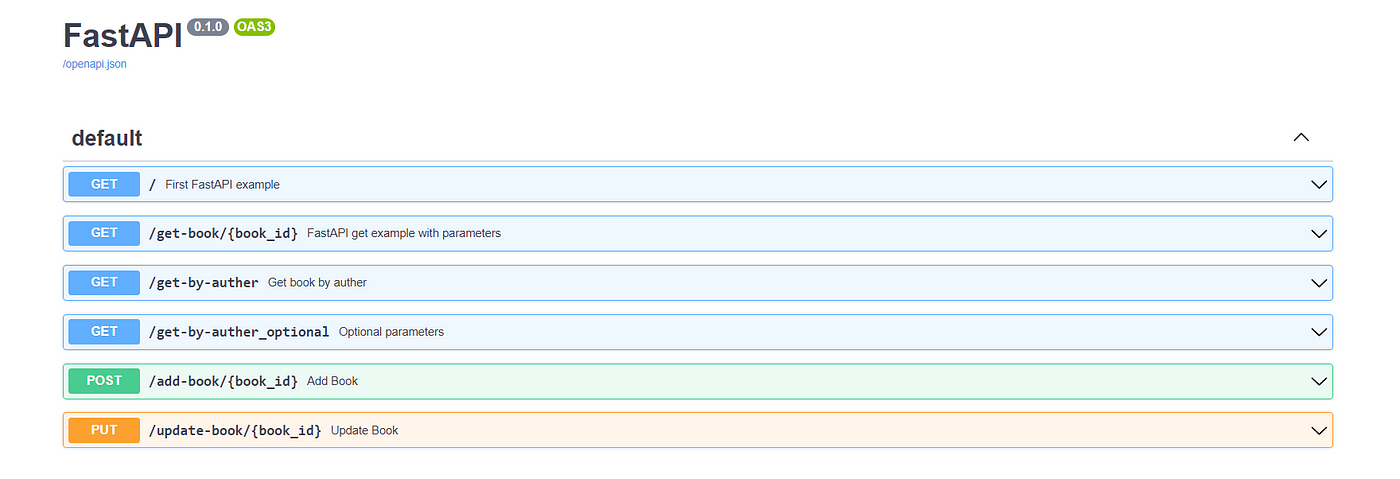
Python kubeflow vs kubeflow
Python kubeflow vs kubeflow
I'll respond in English as per your request.
Python Kubeflow vs Kubernetes-based Kubeflow: A Comparative Analysis
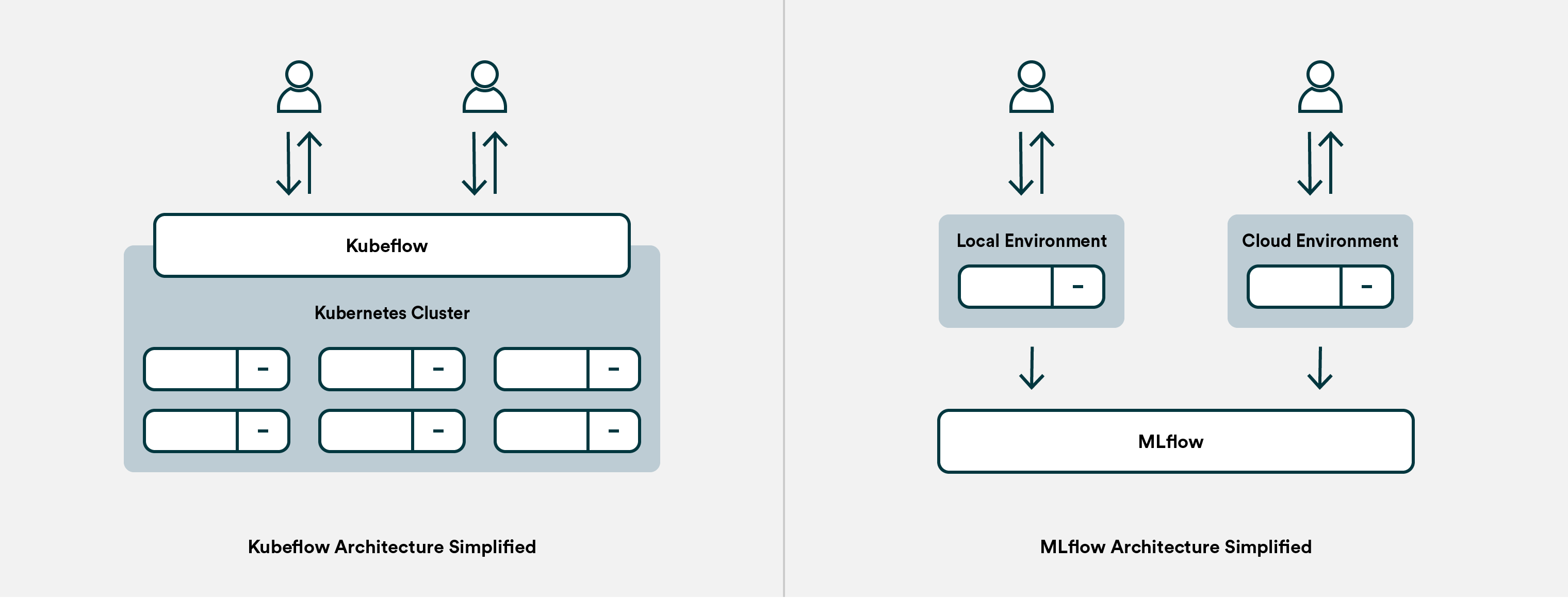
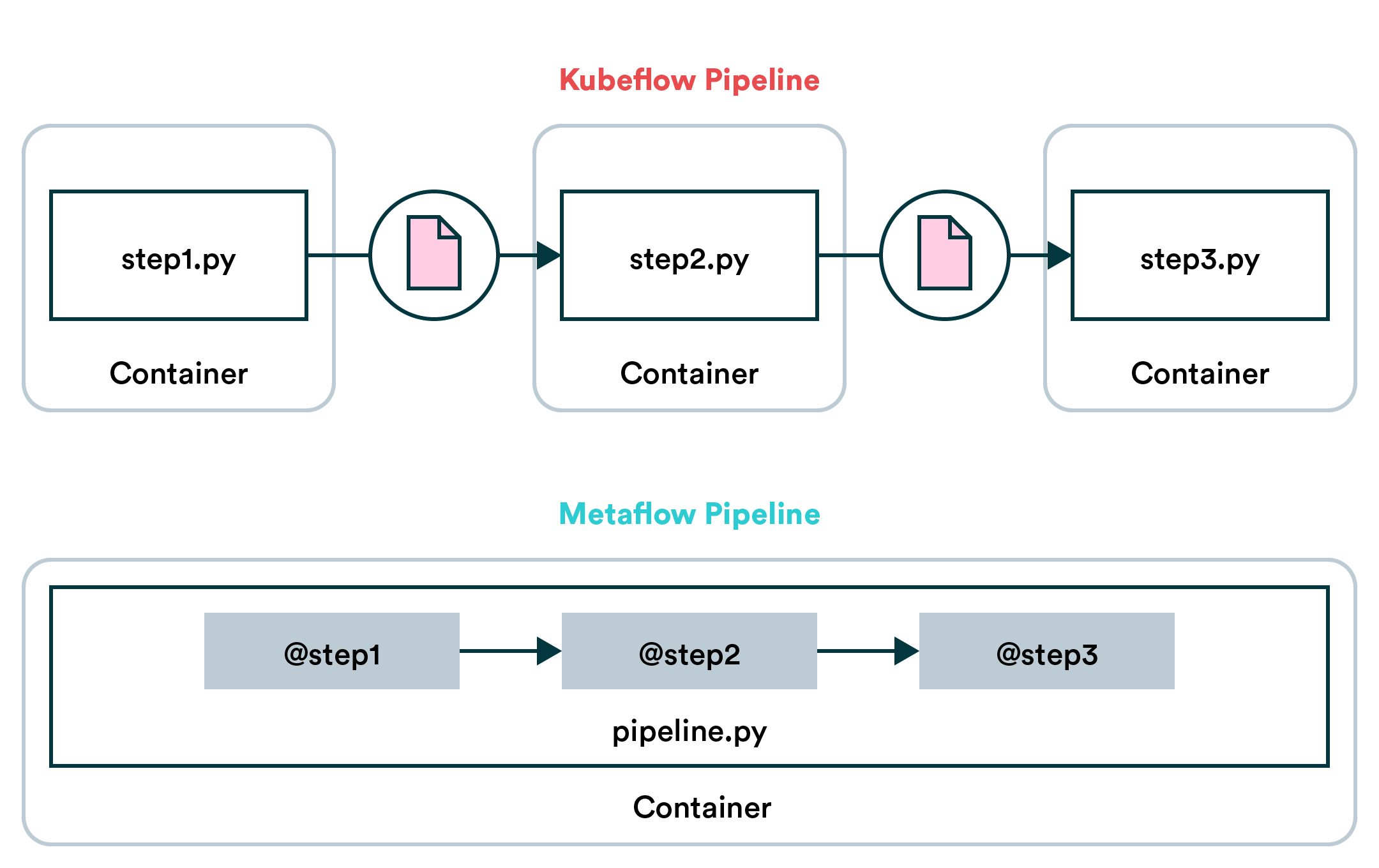
Kubeflow is an open-source platform for machine learning (ML) that automates the ML process from data preparation to deployment. The term "Kubeflow" often confuses developers and data scientists, as it refers to both a Python library and a Kubernetes-based platform. In this response, we'll dive into the differences between these two versions of Kubeflow.

Python Kubeflow (KF- Python)
The original Kubeflow is written in Python and serves as a lightweight framework for building ML pipelines. It's designed to simplify the workflow from data preparation to model deployment by providing pre-built functions, such as data ingestion, feature engineering, and model training. KF-Python allows users to define workflows using Python code, making it easy to integrate with existing data science tools and libraries.
Key features of KF-Python:
Kubernetes-based Kubeflow (KF-K8s)
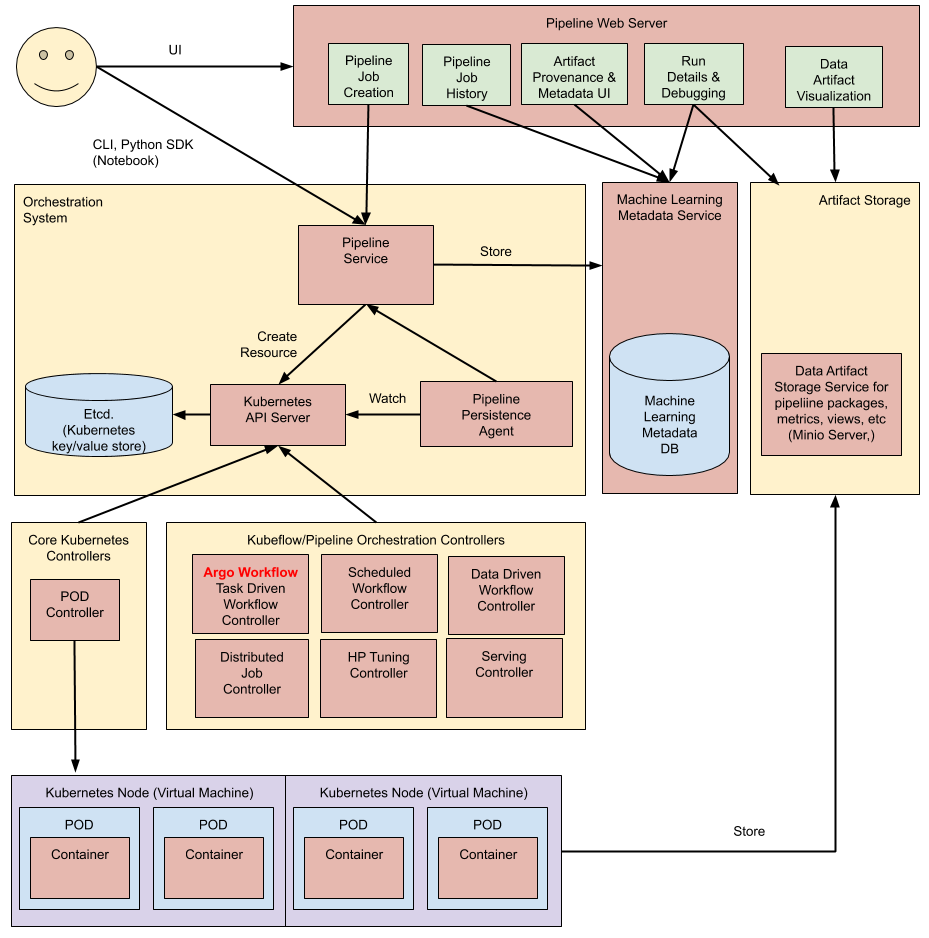
The Kubernetes-based Kubeflow is a more recent development that leverages the power of containerization and orchestration provided by Kubernetes. This version of Kubeflow is designed to scale ML workflows seamlessly across clusters, nodes, or even cloud providers. KF-K8s provides a managed platform for deploying ML models in production environments, ensuring reliability, scalability, and maintainability.
Key features of KF-K8s:
Kubernetes-based deployment: Kubeflow uses Kubernetes to deploy ML models in production environments, providing scalability, reliability, and maintainability. Containerized workflows: KF-K8s enables users to containerize their ML workflows, making it easy to manage dependencies and versions. Integration with popular ML frameworks: Kubeflow supports integration with popular machine learning frameworks such as TensorFlow, PyTorch, and scikit-learn.Comparison
While both versions of Kubeflow share the same goals – simplifying ML pipelines and scaling ML workflows – there are significant differences between KF-Python and KF-K8s:
Scalability: KF-K8s is designed to scale ML workflows across clusters, nodes, or cloud providers, whereas KF-Python is more focused on local workflow development. Deployment: KF-Python typically deploys ML models using Python's built-in deployment mechanisms (e.g., Flask or Django), while KF-K8s uses Kubernetes for production-ready deployments. Integration: Both versions of Kubeflow integrate with popular machine learning libraries, but KF-K8s provides more robust support for containerized workflows and orchestration.Conclusion
In conclusion, Python Kubeflow (KF-Python) is a lightweight framework designed for local workflow development, integration, and deployment. Kubernetes-based Kubeflow (KF-K8s), on the other hand, is a managed platform that leverages containerization and orchestration to scale ML workflows across clusters or cloud providers.
When choosing between these two versions of Kubeflow, consider the following:
Local workflow development: If you're looking to develop and deploy ML workflows locally, KF-Python might be the better choice. Scalable production deployments: If you need to deploy ML models in a production-ready environment that can scale across clusters or cloud providers, KF-K8s is likely the way to go.I hope this response has provided valuable insights into the differences between Python Kubeflow and Kubernetes-based Kubeflow.
Python kubeflow github
Here is a detailed response about Python Kubeflow and GitHub:
Kubeflow (https://www.kubeflow.org/) is an open-source platform that aims to make Machine Learning (ML) workflow management and deployment more efficient, scalable, and collaborative. Developed by the Kubeflow community, it builds upon Kubernetes and other popular ML frameworks like TensorFlow, PyTorch, and scikit-learn.
What is Kubefrow?

Kubeflow provides a suite of tools and services for automating the ML workflow, including data preparation, model training, hyperparameter tuning, model deployment, and model serving. It enables data scientists to focus on their work rather than worrying about infrastructure and scalability issues. By leveraging Kubernetes, Kubeflow provides containerized environments for each step in the ML pipeline, making it easy to reproduce and scale experiments.
Key Features:
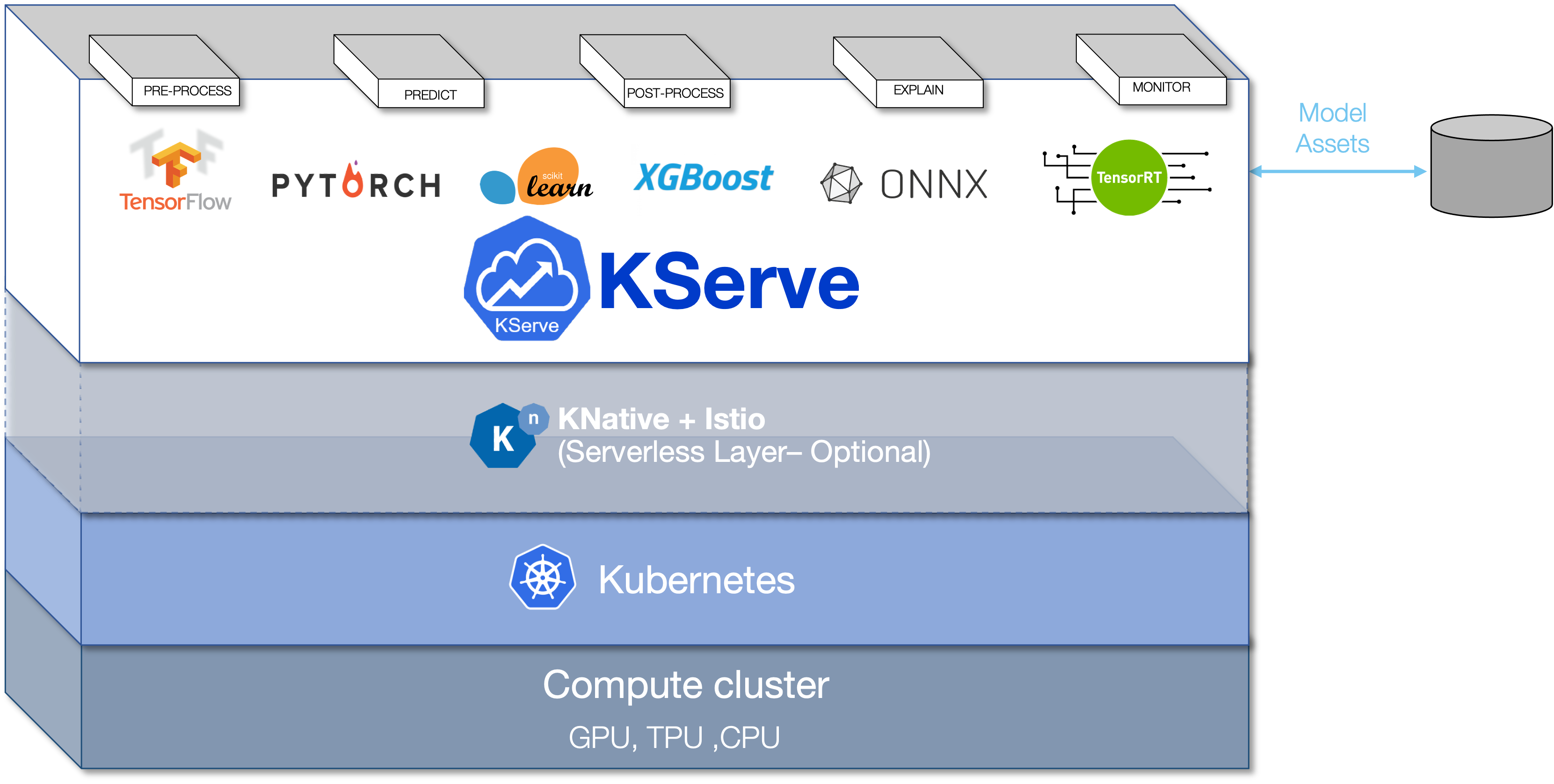
Kubeflow Pipelines: This feature allows data scientists to define ML workflows using a Python-based DSL (Domain-Specific Language). Pipelines can be composed of various tasks, such as data ingestion, preprocessing, model training, hyperparameter tuning, and evaluation. Jupyter Notebook Integration: Kubeflow integrates seamlessly with Jupyter Notebooks, enabling data scientists to easily create, edit, and run notebooks within the Kubeflow environment. Containerized Environments: Kubeflow uses containerization (via Docker) to manage dependencies and ensure reproducibility across environments. This feature allows for easy migration of ML experiments between development, testing, and production environments. Model Serving: Once a model is trained and deployed, Kubeflow provides Model Serving, which enables serving and scoring the model using TensorFlow Serving or other serving frameworks.GitHub:
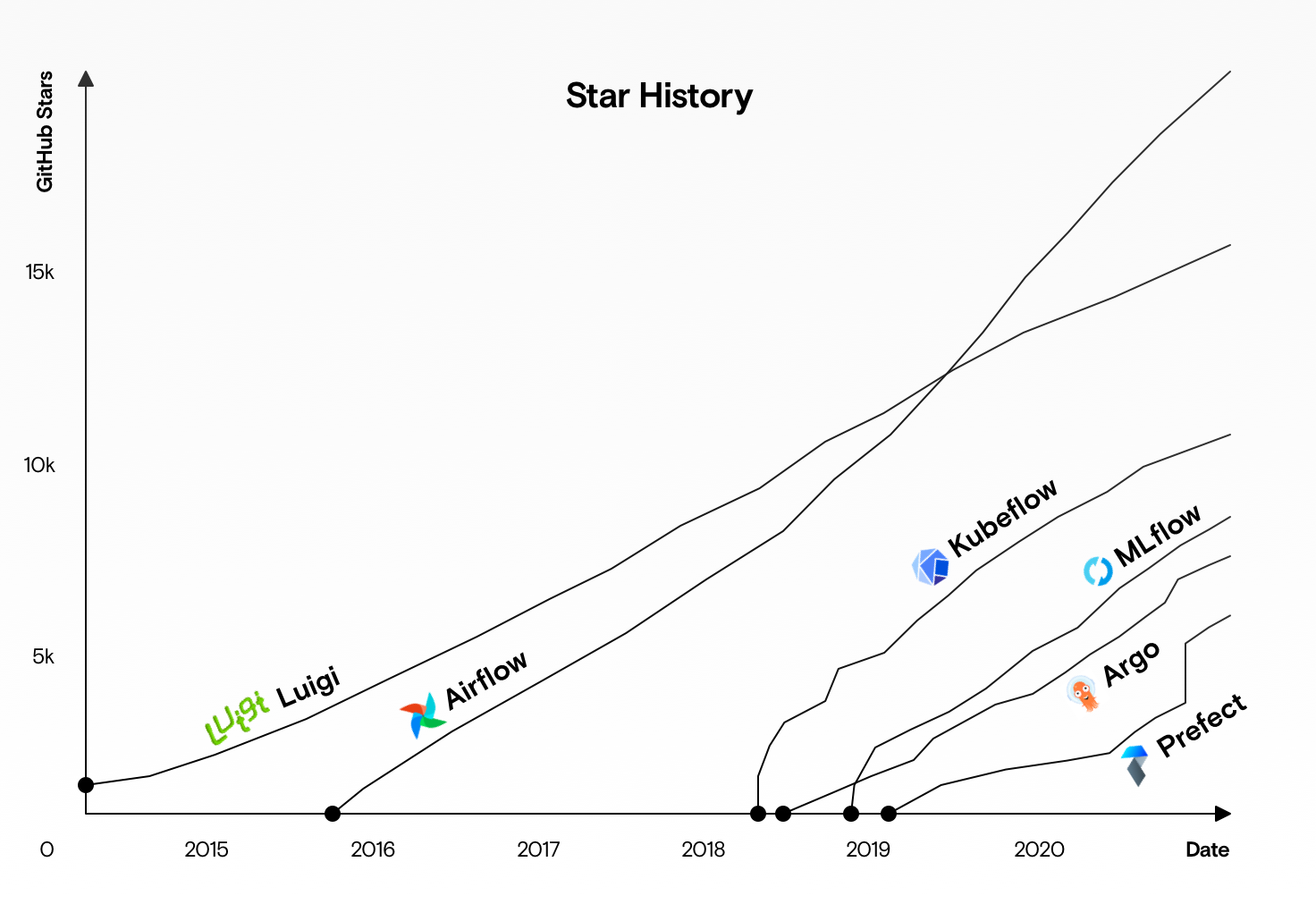
Kubeflow is open-source and has an active community on GitHub (https://github.com/kubeflow). The repository contains the source code for Kubeflow's core components, including the Kubernetes Operator, Python SDK, and other dependencies. This allows contributors to review, modify, and extend the platform according to their needs.
Why Use Kubeflow?
Simplify ML Workflow Management: By automating and streamlining the ML workflow, data scientists can focus on higher-level tasks like feature engineering, model development, and hyperparameter tuning. Ensure Reproducibility: Kubeflow's containerized environments and version control ensure reproducibility across different environments, making it easier to collaborate with others or reproduce results later. Faster Experimentation: With Kubeflow, data scientists can quickly spin up new environments for experimentation, reducing the time spent on setup and configuration.Conclusion:
Kubeflow provides a comprehensive platform for managing Machine Learning workflows, allowing data scientists to focus on their work rather than worrying about infrastructure and scalability issues. By leveraging Kubernetes and other popular ML frameworks, Kubeflow offers a flexible, scalable, and collaborative environment for automating the ML workflow. With an active community on GitHub, Kubeflow continues to evolve and improve, making it an attractive choice for data scientists working with Machine Learning.
I hope this information helps!