K fold cross validation Python code from scratch
K fold cross validation Python code from scratch
I'd be happy to provide you with the K-fold cross-validation code in Python!
What is K-fold Cross-Validation?
K-fold cross-validation is a popular technique used in machine learning to evaluate the performance of a model on unseen data. It's particularly useful when we have limited labeled data or want to make predictions on new, unseen instances.
In traditional cross-validation, we split our dataset into two parts: training and testing sets. We train the model on the training set and then use it to predict the test set. However, this approach can lead to overfitting because the model is trained solely based on the training data.
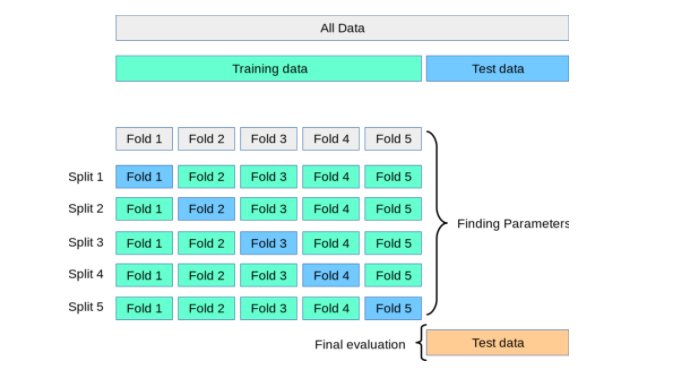
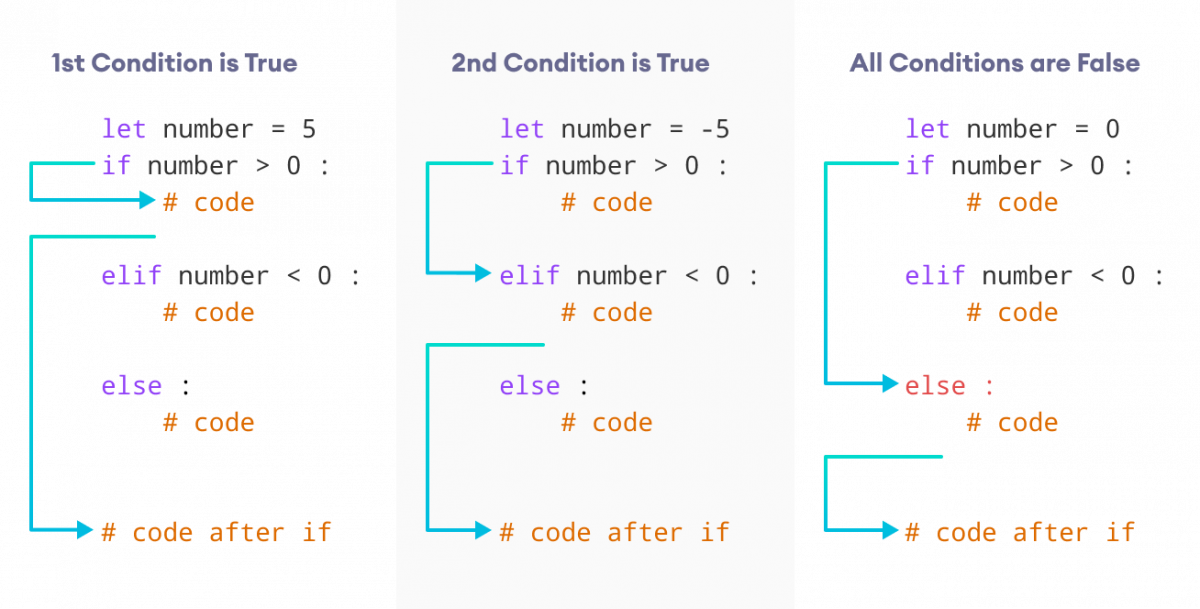
K-fold cross-validation addresses this issue by dividing the dataset into K folds (subsets). The model is trained on K-1 folds and tested on the remaining fold. This process is repeated for each of the K folds, ensuring that every instance in the dataset is used for both training and testing at least once.
The Code
Here's a Python code example using scikit-learn's KFold class to implement k-fold cross-validation:
import numpy as npfrom sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score, classification_report
Load your dataset (e.g., Iris dataset)from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)
Define the model and hyperparameters (for simplicity, let's use a random forest classifier)from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=100, max_depth=5)
Set k-fold cross-validation parametersn_fold = 5 # Number of folds
Initialize KFold object with n_foldskf = KFold(n_splits=n_fold, shuffle=True, random_state=42)
Define a function to evaluate the model on each folddef evaluate_model(model, X, y):
predictions = []
for train_index, val_index in kf.split(X):
X_train, X_val = X[train_index], X[val_index]
y_train, y_val = y[train_index], y[val_index]
Train the model on the training setmodel.fit(X_train, y_train)
Make predictions on the validation sety_pred = model.predict(X_val)
Append the predictions to a listpredictions.append(y_pred)
return predictions
Evaluate the random forest classifier using k-fold cross-validationrf_predictions = evaluate_model(rf, X, y)
How the Code Works
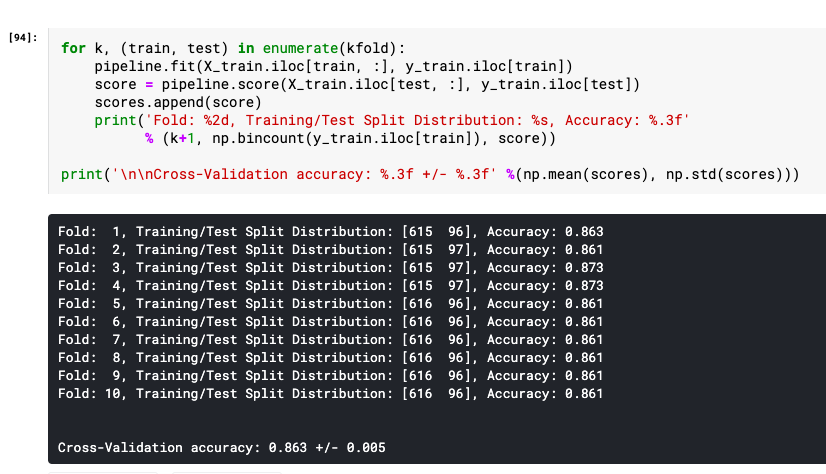
We load the Iris dataset and define our model (a random forest classifier) with hyperparameters. We set the number of folds (n_fold) to 5, which means we'll divide the data into 5 equal subsets. We initialize a KFold object with the specified number of folds, shuffle the data for randomization, and set a random state for reproducibility. Define an evaluate_model function that trains the model on each fold (training set) and makes predictions on the corresponding validation set. We store these predictions in a list called predictions. Finally, we call the evaluate_model function with our model and dataset to obtain the predictions for each fold.
What's Next?
Now that you have the code, you can modify it to suit your specific needs:
Load your own dataset instead of the Iris dataset. Experiment with different models and hyperparameters. Plot the average accuracy or other performance metrics across folds usingmatplotlib or seaborn. Compare the results to a baseline model (e.g., a random predictor).
Remember to adjust the code according to your specific problem, and don't hesitate to ask if you have any questions!
What is the Kfold method in Python?
I'm happy to help you with that!
K-Fold Cross Validation (KFCV) is a popular technique used in machine learning and statistics to evaluate the performance of various models, especially those trained on limited data sets. The concept was first introduced by Stone in 1974.
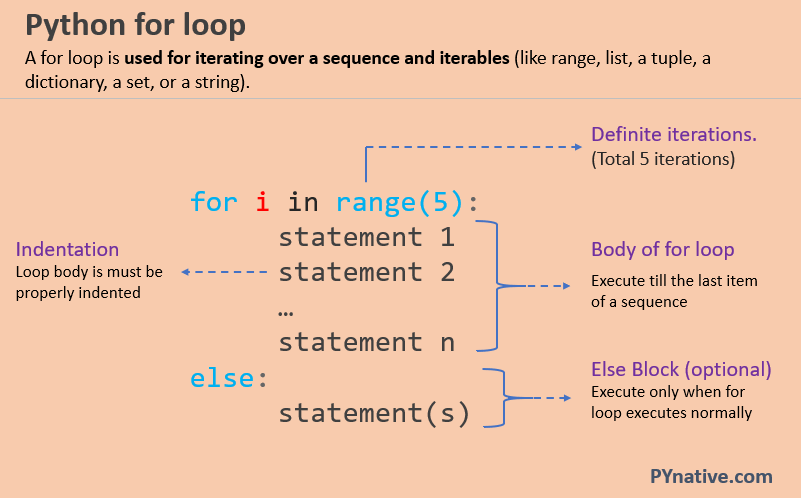
In K-Fold Cross Validation, your dataset is divided into k-folds or subsets, typically k=5 or k=10, depending on the size and complexity of your data. Each fold contains roughly the same proportion of samples as the original dataset.
Here's how it works:
Initialization: Choose a model, e.g., logistic regression, decision tree, random forest, neural network, etc. Folding: Divide your dataset into k-folds. You can do this using various libraries like scikit-learn in Python. Training and Evaluation:a. Train the model on k-1 folds (i.e., k-1 subsets of the data).
b. Use the remaining 1 fold as test data to evaluate your trained model's performance. This is done by predicting labels for this 1-fold, then comparing them with the actual labels.
c. Calculate metrics like accuracy, precision, recall, F1-score, or Mean Squared Error (MSE), depending on your problem type and evaluation goals.
Repeat: Repeat steps 3a-c for each fold, ensuring that each sample is used once as test data.By doing this k-fold cross-validation, you get an idea of how well your model generalizes to unseen data. This approach helps:
Avoid overfitting: By testing your model on different subsets of the data, you can detect when it's overly specialized to a specific portion of your dataset. Estimate performance: The average metrics from all k-folds gives you an estimate of how well your model will perform on new, unseen data. Compare models: Use KFCV to compare the performance of different machine learning algorithms or hyperparameters.In Python, you can implement K-Fold Cross Validation using libraries like scikit-learn and pandas. Here's a simple example with scikit-learn:
from sklearn.model_selection import KFold assume X is your feature matrix and y is your target variablekf = KFold(n_splits=5, shuffle=True)
for train_index, val_index in kf.split(X):
X_train, X_val = X.iloc[train_index], X.iloc[val_index]
y_train, y_val = y.iloc[train_index], y.iloc[val_index]
Train and evaluate your model here using X_train and y_train
Remember to choose an appropriate number of folds (k) based on the size and complexity of your dataset. A larger k may lead to more accurate results but also increases computation time.
That's it! I hope this explanation was helpful in understanding K-Fold Cross Validation in Python.