Python aiohttp vs requests
Python aiohttp vs requests
When it comes to making HTTP requests in Python, there are several options available. Two popular libraries for this purpose are aiohttp and requests. In this comparison, we will explore the differences between these two libraries and determine which one is more suitable for your needs.
Requests
The requests library is a widely used and well-established tool for making HTTP requests in Python. It provides an easy-to-use interface for sending HTTP requests and parsing HTTP responses. Here are some key features of the requests library:

requests library uses synchronous I/O, which means that it will block your program until the request is completed. Supports various protocols: In addition to HTTP, the requests library also supports HTTPS, FTP, and more. Parses responses: The requests library can parse JSON, XML, and other response formats for you. Easy to use: The API of the requests library is simple and easy to understand.
However, there are some limitations to using the requests library. One major drawback is that it uses synchronous I/O, which can lead to performance issues if your program needs to make many requests at once.
Aiohttp
The aiohttp library, on the other hand, is a Python 3.5+ library for building asynchronous HTTP clients and servers. Here are some key features of the aiohttp library:
aiohttp library uses asynchronous I/O, which means that it will not block your program until the request is completed. Supports various protocols: Like the requests library, the aiohttp library also supports HTTPS, FTP, and more. Parses responses: The aiohttp library can parse JSON, XML, and other response formats for you. Easy to use: The API of the aiohttp library is simple and easy to understand.
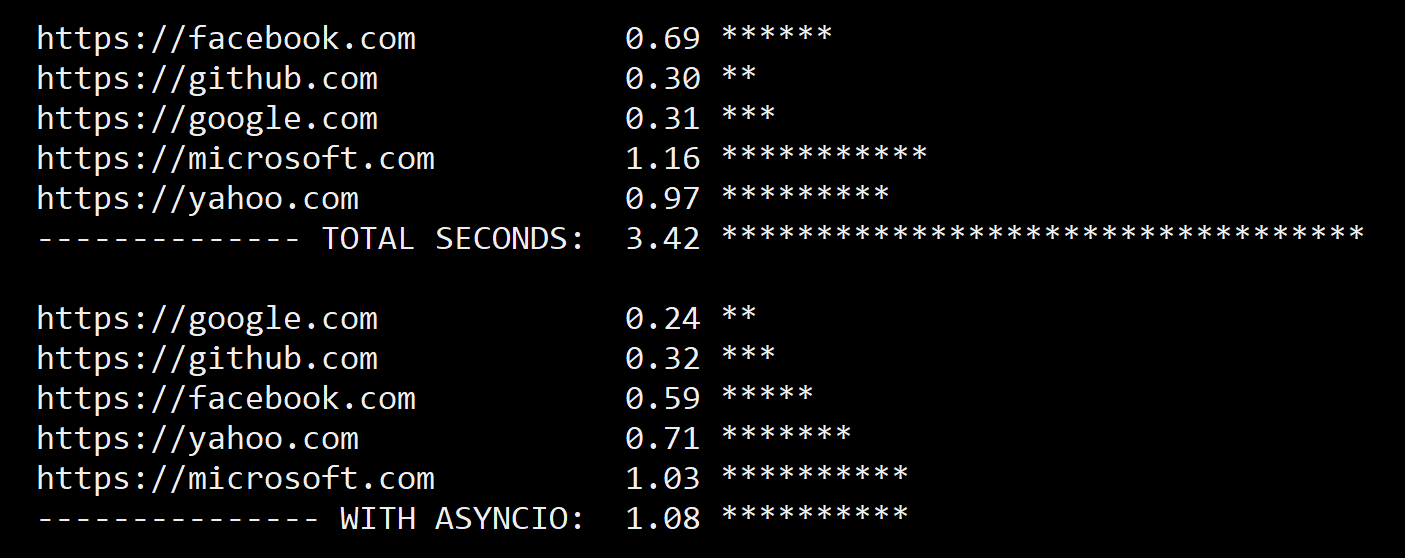
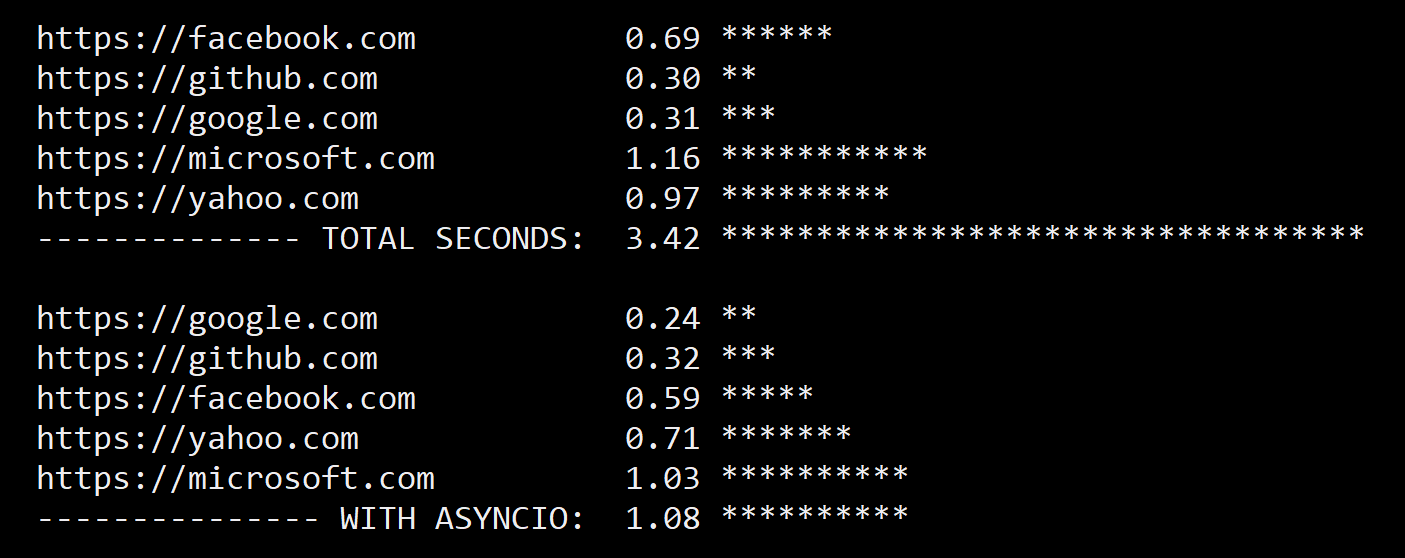
One major advantage of using the aiohttp library is that it allows your program to make multiple requests concurrently without blocking. This makes it particularly useful when working with APIs that require a lot of requests, such as when scraping data or making calls to an API that requires authentication.
Comparison
In summary, here are some key differences between the requests and aiohttp libraries:
| | Requests | Aiohttp |
| --- | --- | --- |
| I/O Method | Synchronous | Asynchronous |
| Use Case | Simple requests, small-scale use cases. | Large-scale, concurrent requests. |
Conclusion
In conclusion, both the requests and aiohttp libraries have their own strengths and weaknesses. If you are making simple HTTP requests and do not need to make multiple requests concurrently, then the requests library may be a good choice for you. However, if you are working with APIs that require a lot of requests, or if you need to make concurrent requests without blocking your program, then the aiohttp library may be a better option.
Real-world examples
Here are some real-world scenarios where one library might be more suitable than the other:
If you are building a simple web scraper that makes a few requests and does not require concurrency, then therequests library would be a good choice. If you are building an API client that needs to make many concurrent requests without blocking your program, then the aiohttp library would be a better option.
In summary, when deciding between requests and aiohttp, consider the number of requests you need to make and whether concurrency is important.
Aiohttp Python example
Here's a basic example of using aiohttp, a popular asynchronous web framework for Python:
import asyncio
from aiohttp import web
async def handle_request(request):
name = request.match_info.get('name', 'Anonymous')
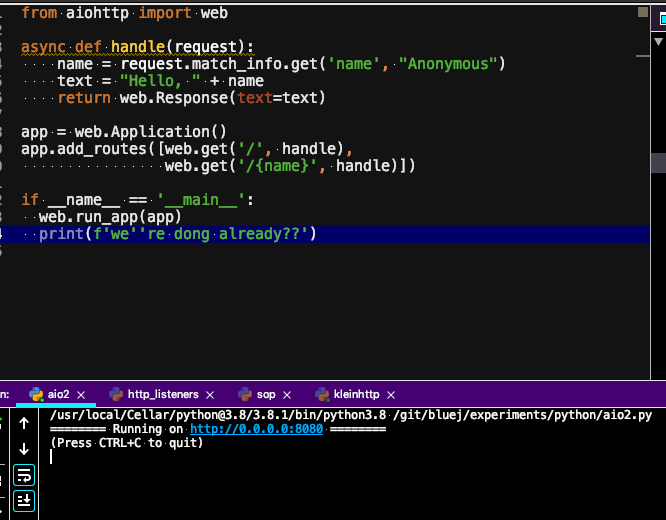
text = f"Hello, {name}!"
return web.Response(text=text)
app = web.Application()
app.add_routes([web.get('/hello/{name}', handle_request)])
if name == 'main':
web.run_app(app, port=8000)
This script sets up a simple web server that responds to requests on the /hello/<name> route. When a request is made to this route, it returns a greeting message with the name passed in the URL.
The handle_request function is an asynchronous function that handles incoming HTTP requests. This means that it can handle multiple requests simultaneously without blocking each other, which makes it well-suited for handling a high volume of requests.
In this example, the handle_request function uses the match_info property of the request to get the value of the {name} parameter in the URL. If no name is provided, it defaults to 'Anonymous'.
The app object represents the application. We use the add_routes method to add the /hello/<name> route to the app. The route points to the handle_request function.
Finally, we start the server by calling the run_app method with the app and a port number (8000 in this case). This starts the server listening for incoming requests on that port.
Now let's use this example as a starting point to build a real-world web application. Here are some things you might want to consider:
Error handling: In a real-world application, you would likely need to handle errors differently than just raising an exception and letting it crash the server. You could use try-except blocks or error-handling middleware. Request processing: Thehandle_request function is quite simple. In a real-world application, you might want to extract information from the request (like form data), store data in databases or caches, perform calculations or API calls, etc. Response formatting: This example just returns plain text. Depending on your needs, you might need to format the response as JSON or HTML, handle file uploads, etc. Security and validation: You would want to validate user input and ensure that it doesn't pose a security risk. This could include things like filtering out malicious data, handling CORS correctly, and implementing rate limiting or IP blocking. Session management: Depending on your application's needs, you might need to manage sessions (like storing user login information) or handle authentication/authorization.
Here are some tips for building scalable and efficient web applications:
Use asynchronous I/O: aiohttp does this automatically. You should prioritize using asynchronous I/O operations over synchronous ones whenever possible. Use connection pooling: Many databases and caches can benefit from connection pooling to improve performance. Make sure you're not opening too many connections at once, and consider using a connection pooler likeasyncpg. Don't block the event loop: Remember that your event loop is what makes aiohttp so efficient! Don't use synchronous operations inside asynchronous code or you might block the event loop. Use a real database: Databases are usually faster than storing data in memory. Use a database like SQLite, PostgreSQL, or MySQL to store data instead of relying on RAM. Profile and optimize: Once your application is built, use profiling tools (like line_profiler or cProfile) to identify performance bottlenecks and optimize accordingly.