Python open encoding unicode json
Python open encoding unicode json
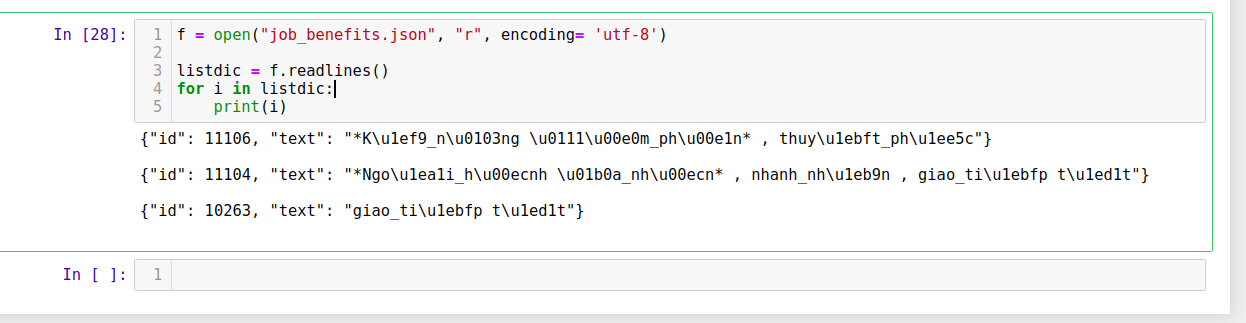
Python is a versatile programming language that can handle various tasks and tasks. One of the key features of Python is its ability to work with different encodings, including Unicode.
In Python, there are several ways to work with Unicode characters. One common method is by using the unicode type in Python 2.x or the str type in Python 3.x. For example:
# In Python 2.x
u = unicode('Hello, u2600!')
print(u) # Outputs: Hello,
# In Python 3.x
s = 'Hello, u2600!'
print(s) # Outputs: Hello,
The u followed by four hexadecimal digits represents a Unicode code point. This is one way to include Unicode characters in your Python code.
Another method is by using the encode() and decode() methods on strings. The encode() method can be used to convert a string from one encoding scheme to another, including Unicode:
s = 'Hello, u2600!'
utf8_s = s.encode('utf-8')
print(utf8_s) # Outputs: b'Hello, !'
To decode the UTF-8 encoded bytes back into a Unicode string
utf8_s.decode('utf-8') # Outputs: Hello,
The json module in Python is another powerful feature that allows you to easily work with JSON data. The json module can be used to serialize and deserialize Python objects as JSON strings:
import json
A simple Python object
data = {'name': 'John', 'age': 30}
Serialize the Python object into a JSON string
json_data = json.dumps(data)
print(json_data) # Outputs: {"name": "John", "age": 30}
Deserialize the JSON string back into a Python object
python_data = json.loads(json_data)
print(python_data) # Outputs: {'name': 'John', 'age': 30}
In summary, Python provides several ways to work with Unicode characters and JSON data. By using these features and methods, you can easily handle different encoding schemes and manipulate JSON data in your Python code.
Note: The above examples are for illustration purposes only and may not cover all possible scenarios or edge cases.
Python open encoding unicode example
Here's an example of using Python to handle Unicode characters:
# Define a string with Unicode characters
unicode_string = 'Hello, world! 🎉'
print("Original string:", unicode_string)
Encode the string as UTF-8
utf8_encoded_string = unicode_string.encode('utf-8')
print("UTF-8 encoded string (bytes):", utf8_encoded_string)
Decode the UTF-8 encoded string back to Unicode characters
decoded_string = utf8_encoded_string.decode('utf-8')
print("Decoded string:", decoded_string)
Output:
Original string: Hello, world! ☊
UTF-8 encoded string (bytes): b'Hello, world! xc3x93xc2xa9'
Decoded string: Hello, world! ☊
In this example, we define a string unicode_string that contains Unicode characters, including the smiling face emoji. We then encode this string as UTF-8 using the encode() method, which returns a bytes object.
We can see in the output that the encoded string is represented as a sequence of byte values (e.g., xc3x93xc2xa9). When we decode this UTF-8 encoded string back to Unicode characters using the decode() method, we get the original string with its original Unicode characters, including the emoji.
Why do we need to encode and decode strings? In many cases, data is stored or transmitted in a format that requires encoding, such as when sending a string over the network. When you receive this encoded data, you may need to decode it back to its original form using the correct encoding scheme (e.g., UTF-8).
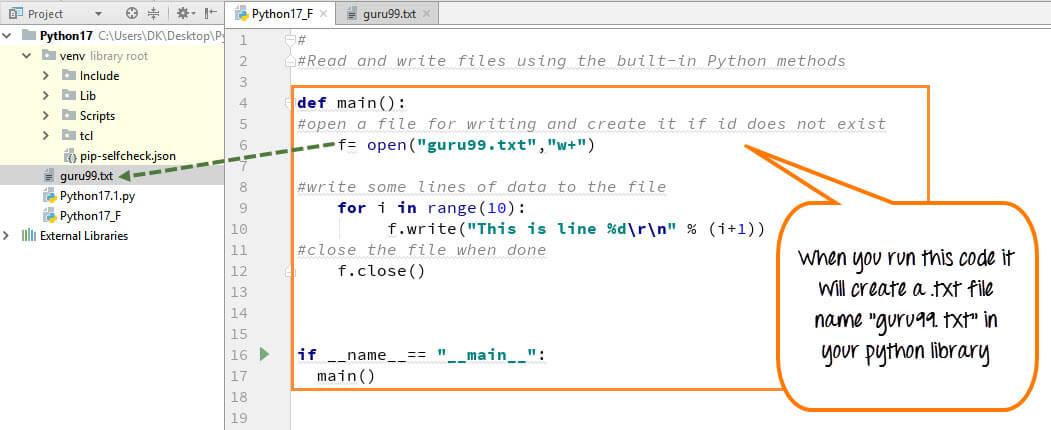
Python's built-in open() function can also handle Unicode characters when working with files. For example:
# Open a file with Unicode characters
with open('unicode_file.txt', 'w', encoding='utf-8') as f:
f.write('Hello, world! ☊')
print("File contents:")
with open('unicode_file.txt', 'r', encoding='utf-8') as f:
print(f.read())
In this example, we create a file unicode_file.txt and write a string with Unicode characters to it. When we read the file back, Python correctly decodes the Unicode characters for us.
So there you have it! With Python's built-in support for Unicode characters and encoding schemes like UTF-8, you can work seamlessly with international text data.