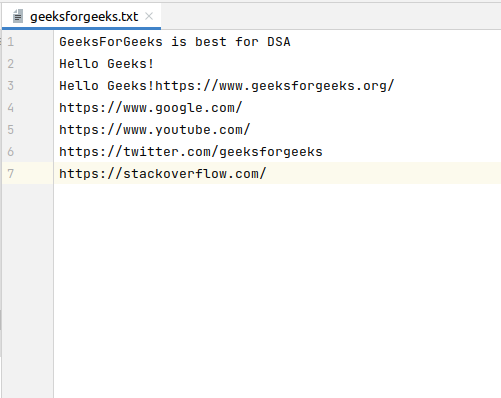
Web scraping Python w3schools
Web scraping Python w3schools
Web scraping with Python is a fantastic topic! W3Schools is an excellent resource for learning web development and programming concepts.
Let's get started with the basics!
Python has several libraries that make it easy to scrape websites. One of the most popular ones is BeautifulSoup, which allows you to parse HTML and XML documents, even if they're messy or malformed.
Here's a simple example:
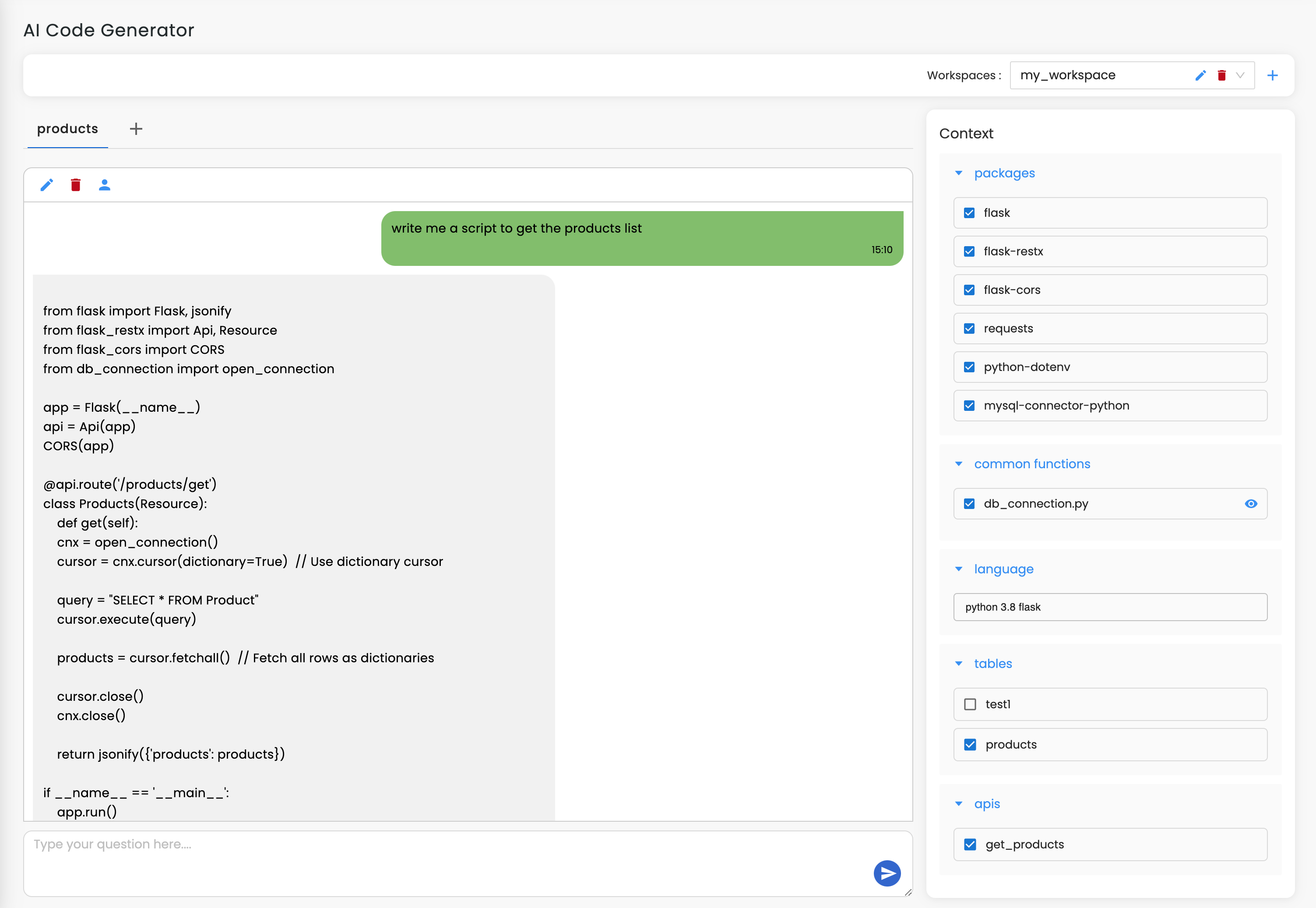
from bs4 import BeautifulSoup
import requests
url = "https://www.w3schools.com/html/default.asp"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.title.string)
In this example, we're using the requests library to get the HTML content of W3Schools' HTML default page. Then, we create a BeautifulSoup object and pass in the HTML content. We can then use various methods and functions provided by BeautifulSoup to navigate and extract data from the HTML document.
Here's another example that extracts all the links on the page:
from bs4 import BeautifulSoup
import requests
url = "https://www.w3schools.com/html/default.asp"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.find_all('a')
for link in links:
print(link['href'])
This code uses the find_all method to find all the <a> tags (which represent hyperlinks) on the page. Then we iterate over each of these links and print out their href attribute, which contains the URL they point to.
W3Schools has many other tutorials and examples that cover various topics such as HTML, CSS, JavaScript, and more! If you're interested in learning web development or Python, W3Schools is definitely a great place to start!
What do you think about using BeautifulSoup for web scraping? Have any questions or suggestions?
How to get Beautiful Soup in Python?

I'm happy to help!
Beautiful Soup is a popular Python library used for parsing and scraping HTML and XML documents. It allows you to navigate and search through the contents of web pages that have been parsed into a parse tree.
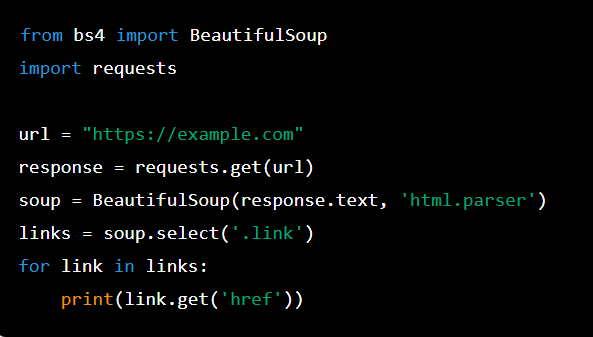
To use Beautiful Soup, you'll need to:
Install the library: You can install Beautiful Soup using pip, which is the Python package manager. Simply runpip install beautifulsoup4 in your terminal or command prompt. Choose a parser: Beautiful Soup needs an external library to parse HTML and XML documents. The most popular parsers are: html5lib: This is a very good parser that supports modern HTML5 syntax. lxml: This is the fastest parser, but it only supports HTML4.1 standard. html.parser: This is the built-in Python parser, which is slow and not recommended for large-scale web scraping projects.
Here's an example of how you can use Beautiful Soup with lxml:
import bs4
Parse a sample HTML file
from bs4 import BeautifulSoup as BS
from lxml import html
html_string = """
Hello, world!
"""
doc = html.fromstring(html_string)
soup = BS(doc, "lxml")
Find all <h1> elements with the class header
headers = soup.find_all("h1", {"class": "header"})
for header in headers:
print(header.text)
Print the contents of the first <body> element
print(soup.body.text)
In this example, we create a sample HTML string and parse it using lxml. We then use Beautiful Soup to find all <h1> elements with the class header and print their text content.
Additional Tips:
Make sure you have the latest version of Python (3.8 or higher) installed. Beautiful Soup works well with HTML5, but if you need to parse older HTML versions, use a different parser. Always handle exceptions when parsing HTML documents, as some may not be valid or contain errors.I hope this helps! If you have any questions or need further clarification, please let me know.