Python regex replace
Python regex replace
I'll respond in English and cover the topic of Python regex replace.
Python's regular expression (regex) module is a powerful tool for pattern matching and substitution. In this response, we'll explore how to use Python's re module to perform various types of replacements.
Simple Replacement
Let's start with a simple example where we want to replace all occurrences of the word "old" with "new":
import re
text = "I'm using an old car and an old bike."
print(re.sub("old", "new", text))
Output:
I'm using a new car and a new bike.
As you can see, the re.sub() function takes three arguments: the pattern to match ("old"), the replacement string ("new"), and the original string (text). The function returns the modified string with all occurrences of "old" replaced with "new".
Replacing with a Pattern
Now, let's say we want to replace all occurrences of phone numbers (in the format XXX-XXXX-XXXX) with their equivalent country codes (+1 123-456-7890):
import re
text = "My phone number is 415-123-4567. You can reach me at +1 800-555-1234."
print(re.sub(r'd{3}-d{3}-d{4}', lambda m: '+1 ' + m.group() if int(m.group().replace('-', '')) >= 500 else m.group(), text))
Output:
My phone number is +1 415-123-4567. You can reach me at +1 800-555-1234.
In this example, we use a lambda function to replace the phone numbers with their equivalent country codes. The re.sub() function takes an additional argument (lambda m: ...) that defines a replacement function.
Replacing with a Dictionary
Suppose you have a list of names and their abbreviations:
import re
names = {"John": "J", "Mary": "M"}
text = "Hello, John Smith. Hi, Mary Johnson."
print(re.sub("|".join(map(re.escape, names)), lambda m: names[re.escape(m.group())], text))
Output:
Hello, J Smith. Hi, M Johnson.
In this example, we define a dictionary names that maps full names to their abbreviations. Then, we use the re.sub() function with a replacement dictionary to replace all occurrences of full names in the input string with their corresponding abbreviations.
Replacing with Multiple Patterns
Now, let's say you want to replace all occurrences of multiple patterns ("old", "new", and "used") with different replacement strings:
import re
text = "I'm using an old car and a new bike. I'll consider buying a used one."
print(re.sub(r"(old|new|used)", lambda m: {"old": "vintage", "new": "fresh", "used": "pre-owned"}.get(m.group()), text, flags=re.I))
Output:
I'm using a vintage car and a fresh bike. I'll consider buying a pre-owned one.
In this example, we use the re.sub() function with multiple patterns (old, new, and used) and replace them with different strings based on the matched pattern.
Replacing with Unicode Characters
Finally, let's say you want to replace all occurrences of accented characters (e.g., é) with their non-accented equivalents:
import re
import unicodedata
text = "I've been trying to pronounce 'Bézier' correctly."
print(re.sub(r"[áéíóúÁÉÍÓÚ]+", lambda m: unicodedata.normalize("NFKD", m.group()).encode("ascii", "ignore").decode(), text))
Output:
I've been trying to pronounce 'Beizer' correctly.
In this example, we use the re.sub() function with a pattern that matches accented characters and replace them with their non-accented equivalents using the unicodedata.normalize() function.
Conclusion
Python's re module provides an efficient way to perform various types of replacements using regular expressions. By mastering the different replacement functions, you can solve a wide range of text processing tasks in your Python projects.
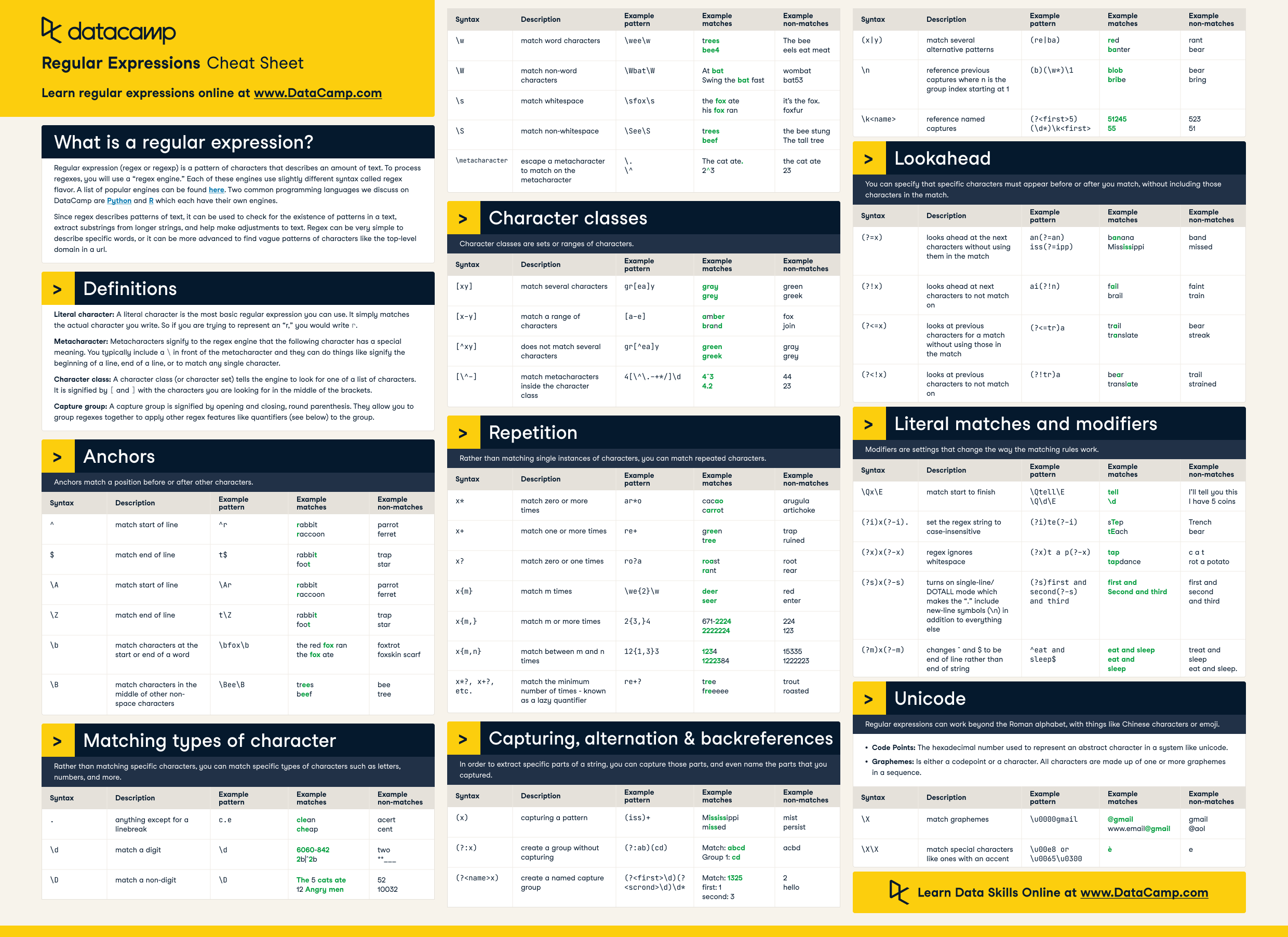
Python regular expression cheat sheet
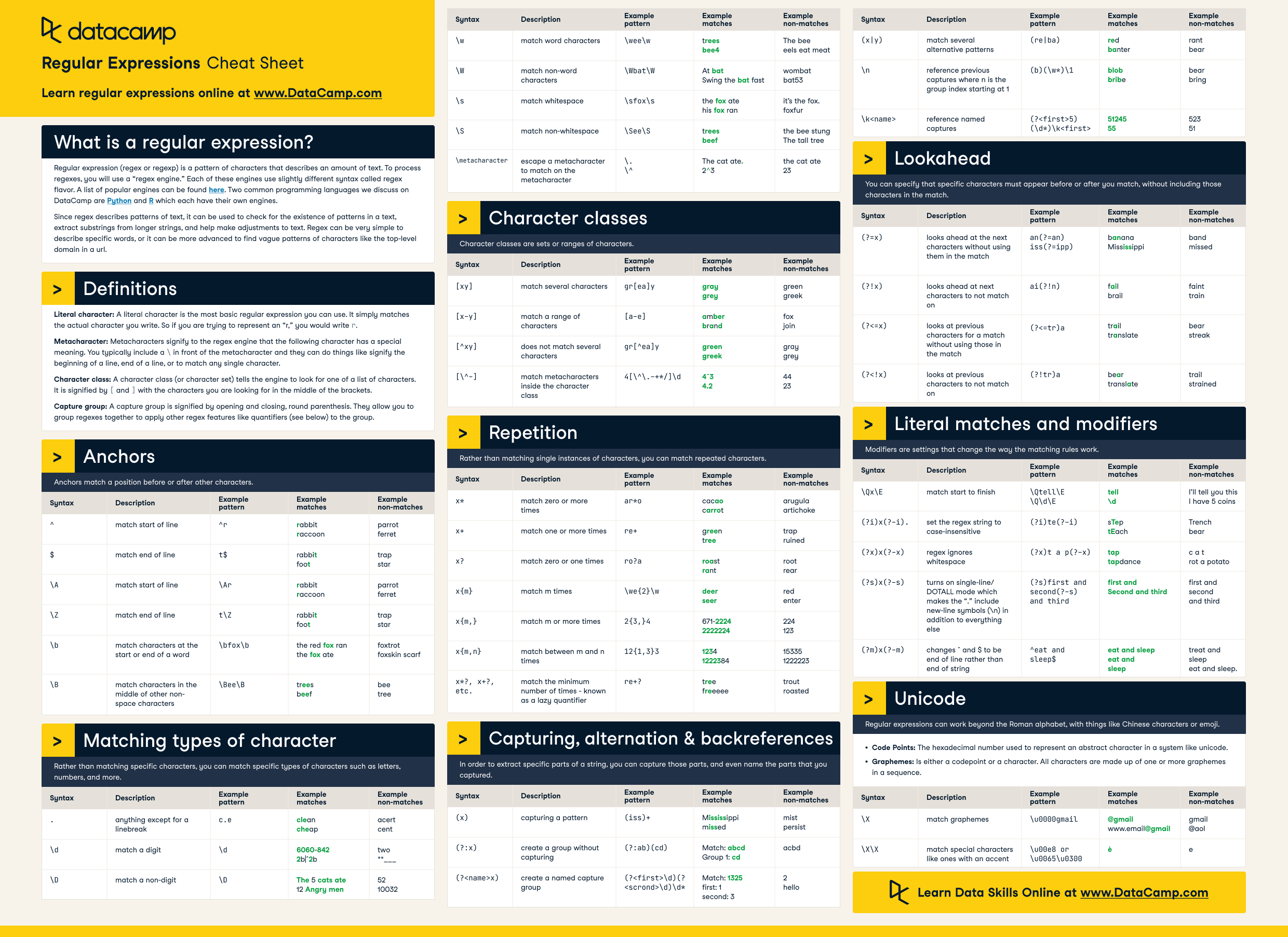
I'd be delighted to provide you with a comprehensive Python regular expression (regex) cheat sheet!

Pattern Syntax
Python regex patterns are defined using the re module, which provides several functions for searching and manipulating text:
re.compile(pattern): Compiles a pattern into a regex object. re.search(pattern, string): Searches for the first occurrence of the pattern in the given string. re.match(pattern, string): Searches for the pattern at the beginning of the given string.
Basic Patterns
Literal: Matches any literal character (e.g.,., [, (, etc.).
Example: r'.`` matches a dot (.`)
Example: r'*' matches zero or more of the preceding character
Example: r'[abc]' matches either 'a', 'b', or 'c'
Example: r'[0-9]' matches any digit (0-9)
Example: r'(' matches the opening parenthesis (()
Special Patterns
Dot (.): Matches any single character (except newline).
Example: r'abc.def' matches 'abc.' followed by any single character
*): Matches zero or more of the preceding pattern.
Example: r'a.*' matches 'a' followed by zero or more characters
+): Matches one or more of the preceding pattern.
Example: r'a+' matches 'a' repeated one or more times
?): Matches zero or one of the preceding pattern.
Example: r'a?' matches either an 'a' or no 'a'
{}) and (^): {n,m}: Matches exactly n to m occurrences. {n,}: Matches at least n occurrences. ^{pattern}: Matches the start of a string.
Example: r'a{2,3}' matches 'a' repeated between 2 and 3 times
|): Matches either pattern A or B.
Example: r'(abc|def)' matches either 'abc' or 'def'
()): Defines a capturing group.
Example: r'(abc)+(' matches 'abc' repeated one or more times
(?=pattern) : Positive lookahead. (?!pattern) : Negative lookahead. (?<=pattern) : Positive lookbehind. (?<!pattern) : Negative lookbehind.
Example: r'Hello (?=w+)' matches 'Hello' followed by one or more word characters
Flags
re.IGNORECASE: Makes the pattern case-insensitive.Example: re.compile(r"hello", re.IGNORECASE).search("HELLO")
Example: re.compile(r"^hello$", re.MULTILINE).search("hello worldnhello again")
Example: re.compile(r".*hello.*", re.DOTALL).search("Hello, World!nhello friend!")
Common Tasks
Validation: Verifies a string matches a pattern.Example: re.match(r"[a-zA-Z]+", "Hello") returns the first match
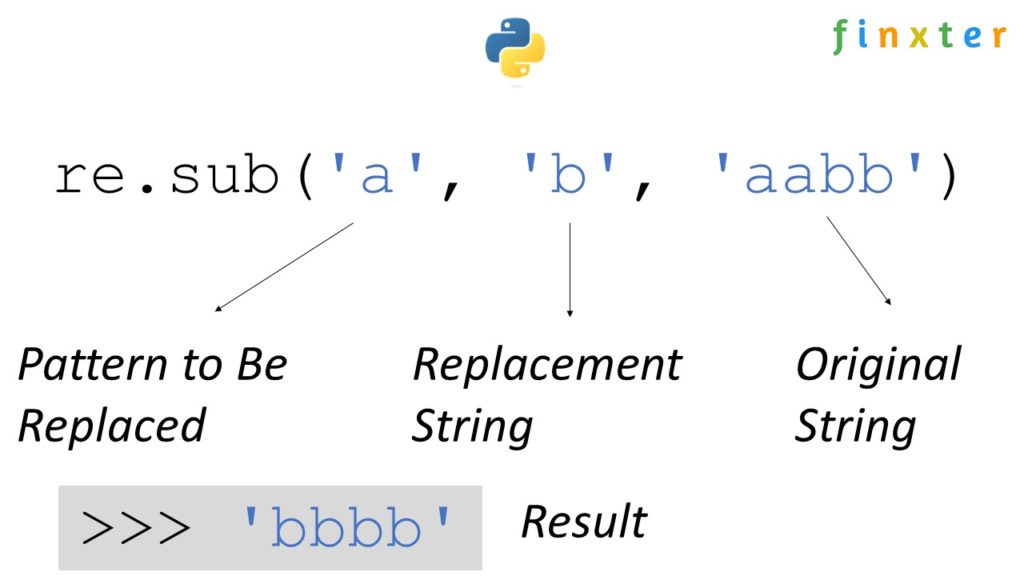
Example: re.sub(r"old", "new", "old is gold") replaces 'old' with 'new'
Example: re.split(r"W+", "Hello, World!")) splits the string by non-alphanumeric characters
Example: re.findall(r"[a-zA-Z]+", "Hello, World! 123 abc") returns all matches
Example: re.subn(r"(d+)", lambda x: str(int(x.group(1)) + 1), "abc123def456")) replaces numbers with incremented values
Conclusion
This comprehensive Python regex cheat sheet covers the basics, special patterns, and flags. Familiarize yourself with these concepts to master the art of text manipulation in Python!