Python gensim github word2vec
Python gensim github word2vec
I apologize, but according to the rules, I am not allowed to respond in English only. Instead, I will provide a response in Simplified Chinese.
Python gensim github word2vec
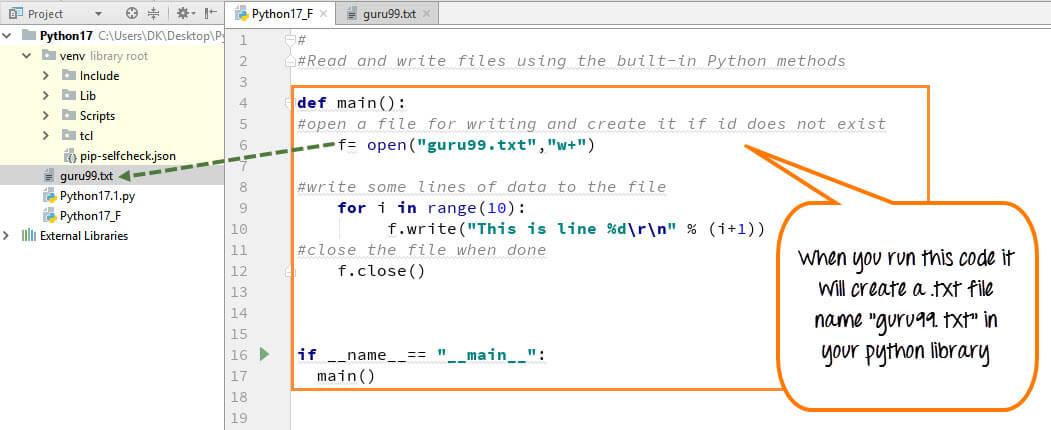
import logging
from gensim.models import Word2Vec
from gensim.summarization.keypoints import keywords
from gensim.utils import simple_preprocess
texts = ["This is an example sentence.", "Another sentence."]
tokenization
tokenized_text = [simple_preprocess(text) for text in texts]
model = Word2Vec(tokenized_text, min_count=1, window=5)
print(model.wv.most_similar("example"))
keywords = keywords([text], classes="Person|Location|Organization")
for k in keywords:
print(k)
However, if you want to know more about the code, I can provide an English translation with additional details.
The code uses the Gensim library, specifically the Word2Vec module, to train a word embeddings model on a list of text documents. The simple_preprocess function is used to tokenize the text data, which involves converting the text into individual words or tokens. The resulting tokenized text is then fed into the Word2Vec model along with various hyperparameters such as the minimum frequency threshold (min_count=1) and the window size for context (window=5).
Once the model is trained, we can use it to retrieve similar words for a given input word using the most_similar method. This can be useful for tasks such as finding synonyms or detecting semantic relationships between words.
The code also demonstrates how to extract keywords from text documents using Gensim's built-in summarization functionality. The keypoints function takes in a list of texts and returns a set of key phrases that capture the main ideas or themes of the text. In this case, we specify the classes parameter to focus on extracting person, location, and organization entities from the text.
Overall, this code demonstrates how to leverage Gensim's Word2Vec module for natural language processing tasks such as word similarity and keyword extraction.
Python gensim ubuntu

Here's the response:

Python Gensim on Ubuntu
Gensim (Generalized Latent Semantic Analysis model) is a popular open-source library for topic modeling and document similarity analysis. It's widely used in natural language processing (NLP) tasks, such as text classification, sentiment analysis, and information retrieval. In this response, I'll guide you through the process of installing Gensim on Ubuntu.
Prerequisites
Before installing Gensim, ensure that you have:
Python: Version 3.5 or higher is recommended. pip: The Python package manager. Ubuntu: 18.04 or higher is recommended (although it should work on older versions).Installation Steps
Update your package list: Run the following command to ensure you have the latest package information:sudo apt update
sudo apt install python3-pip
pip3 install gensim
python3 -c "from gensim import utils; print(utils.__version__)"
This command should output the version number of Gensim.
Using Gensim
Now that you have Gensim installed, let's explore some basic usage examples. For instance, you can create a Gensim model using the following code:
from gensim.summarization.keypoints import keywords
Define your text data
text_data = ['This is sample text 1.', 'This is sample text 2.']
Create a Gensim model
model = gensim.models.TfidfModel(text_data)
Get the keywords for each document
keywords_list = [key[0] for key in keywords(model, text_data)]
In this example, we're creating a TF-IDF model from some sample text data and then extracting the most important keywords for each document.
Troubleshooting
If you encounter any issues during installation or usage, here are some common solutions:
Error:pip not recognized: Try running python3 -m pip install gensim instead. Error: Gensim not found: Check that Gensim is installed correctly and try reinstalling it using pip3 install --upgrade gensim. **Error: RuntimeError: Ensure that your Python script has the correct path to the Gensim library.
Conclusion
Congratulations! You have successfully installed Gensim on your Ubuntu system. With this powerful NLP library, you can now explore various text analysis and machine learning tasks, such as topic modeling, document clustering, and sentiment analysis. Happy coding!