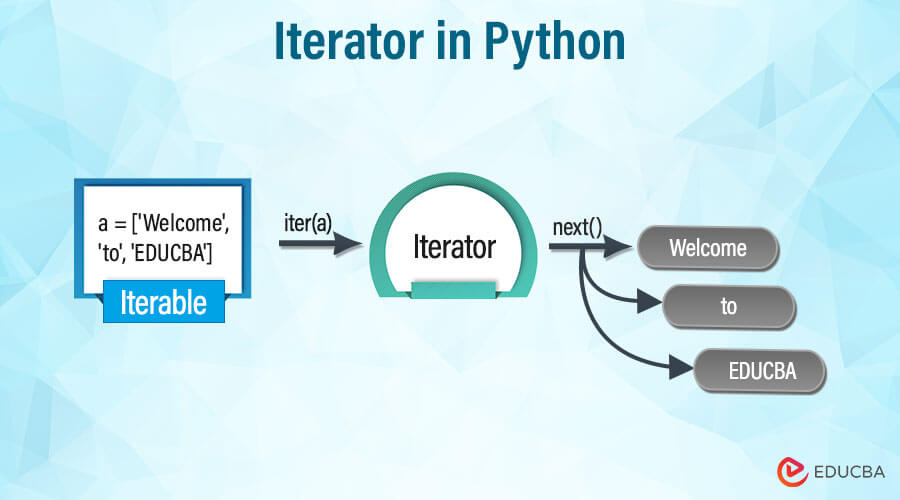
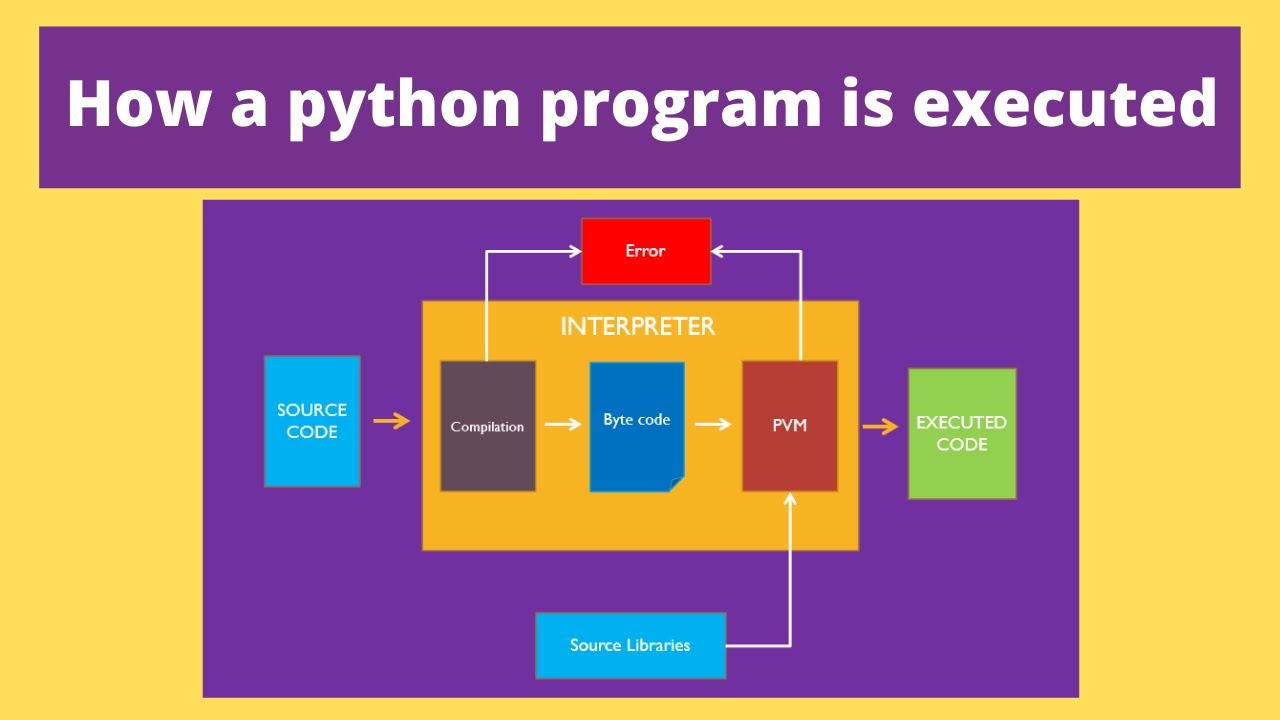
hyperparameter tuning in machine learning python
hyperparameter tuning in machine learning python
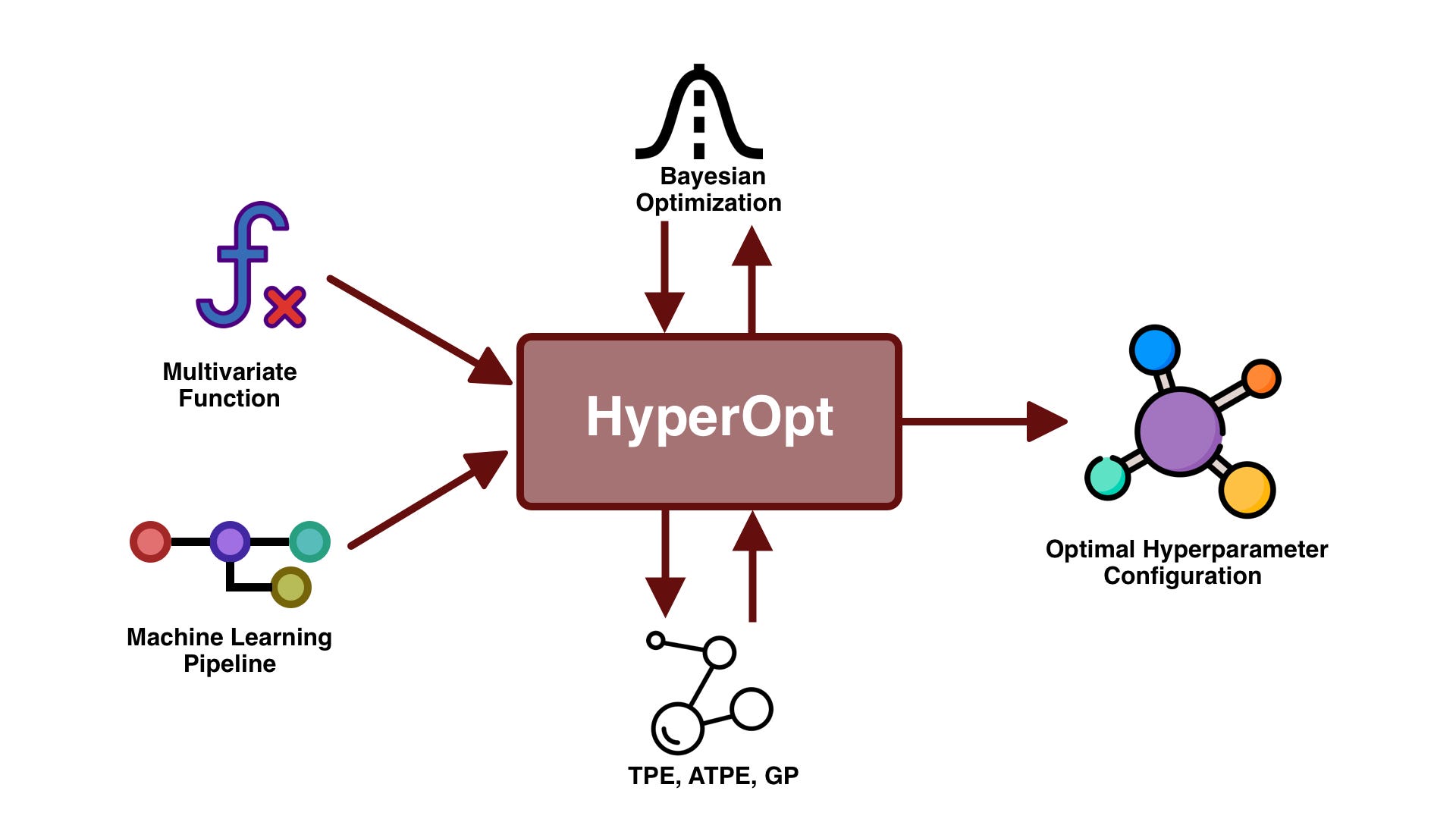
Hyperparameter Tuning in Machine Learning with Python: A Comprehensive Guide
Hyperparameter tuning is a crucial step in the machine learning process that determines how well your model performs. Hyperparameters are variables that need to be set before training a model, and they can significantly impact its performance. In this guide, we'll explore hyperparameter tuning techniques using popular Python libraries like scikit-learn, TensorFlow, and Keras.
Why Hyperparameter Tuning is Important
Before diving into the specifics of hyperparameter tuning, let's briefly discuss why it's essential:
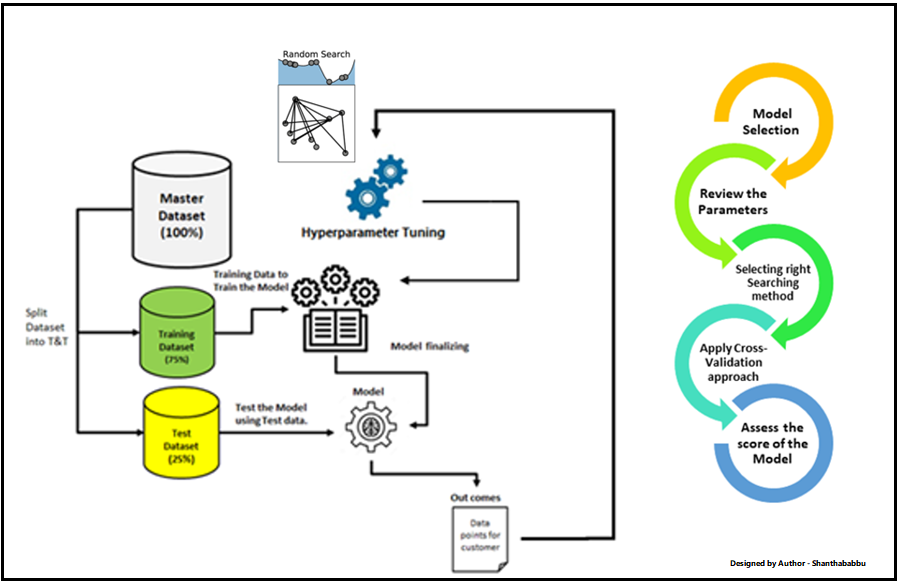
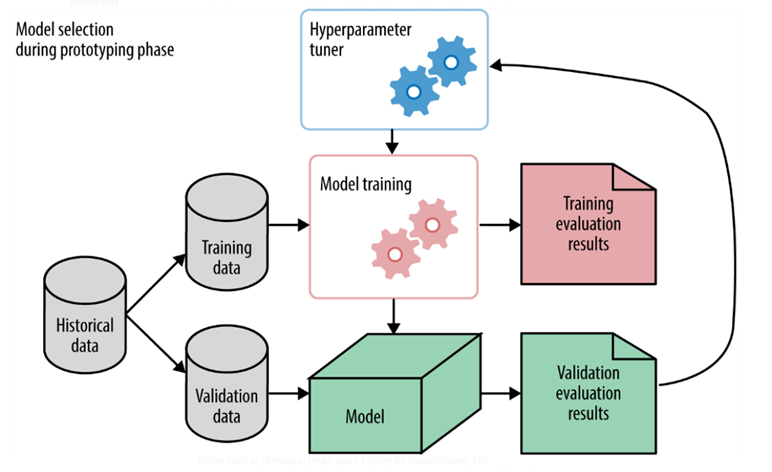

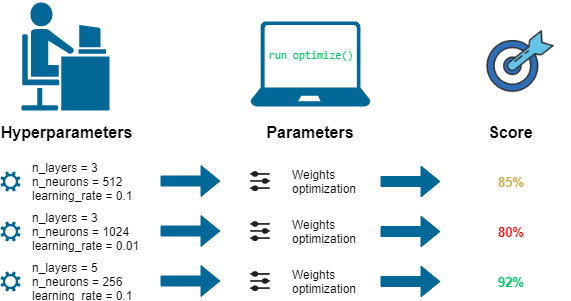
Popular Hyperparameter Tuning Techniques
Grid Search: Exhaustively search a grid of possible hyperparameter values to find the optimal combination. Random Search: Randomly sample hyperparameter combinations, reducing the need for exhaustive searches. Bayesian Optimization: Use probabilistic models to explore the search space and optimize hyperparameters. Gradient-Based Methods: Employ gradient-based optimization techniques, like gradient descent or stochastic gradient descent.Python Libraries for Hyperparameter Tuning
scikit-learn's GridSearchCV: A popular choice for grid search and random search. TensorFlow's Keras: Provides built-in support for grid search and random search through theModelCheckpoint callback. Optuna: An open-source library for Bayesian optimization in Python.
Implementing Hyperparameter Tuning with scikit-learn
Here's an example using scikit-learn's GridSearchCV:
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
Load iris dataset
iris = load_iris()
Define the model and hyperparameter space
rf = RandomForestClassifier()
param_grid = {'n_estimators': [10, 50, 100], 'max_depth': [None, 5, 10]}
Perform grid search
grid_search = GridSearchCV(rf, param_grid, cv=5, scoring='accuracy')
grid_search.fit(iris.data, iris.target)
print("Best Hyperparameters: ", grid_search.best_params_)
print("Best Score: ", grid_search.best_score_)
Implementing Hyperparameter Tuning with Keras (TensorFlow)
Here's an example using Keras and TensorFlow:
import tensorflow as tf
from keras.wrappers import KerasClassifier
Load iris dataset
iris = load_iris()
Define the model and hyperparameter space
model = KerasClassifier(build_fn=lambda: tf.keras.models.Sequential([...])))
param_grid = {'epochs': [1, 5, 10], 'batch_size': [32, 64, 128]}
Perform grid search with ModelCheckpoint callback
grid_search = GridSearchCV(model, param_grid, cv=5, scoring='accuracy', verbose=2)
grid_search.fit(iris.data, iris.target)
print("Best Hyperparameters: ", grid_search.best_params_)
print("Best Score: ", grid_search.best_score_)
In conclusion, hyperparameter tuning is a critical step in machine learning that can significantly impact model performance. By using popular Python libraries like scikit-learn, TensorFlow, and Keras, you can explore various hyperparameter tuning techniques to find the optimal combination for your specific problem.
hyperparameter tuning python sklearn
Hyperparameter Tuning with Python and Scikit-Learn!
What is Hyperparameter Tuning?
In machine learning, hyperparameters are parameters that are set before training a model on your data. For example, the number of hidden layers in a neural network or the maximum depth of a decision tree. Hyperparameter tuning involves finding the optimal values for these parameters to achieve the best performance for your model.
Why is Hyperparameter Tuning Important?
Hyperparameters can significantly impact the performance of your machine learning models. If you don't tune them correctly, your model may not perform well or even worse, overfit or underfit on your data. Hyperparameter tuning helps you find the sweet spot where your model learns from the training data without memorizing it.
How to Perform Hyperparameter Tuning in Python with Scikit-Learn?
Scikit-Learn provides various tools for hyperparameter tuning, including Grid Search and Randomized Search. Here's a step-by-step guide on how to perform hyperparameter tuning using these methods:
Method 1: Grid Search
Import necessary libraries:Load your dataset and split it into training and testing sets:import numpy as npfrom sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score
Define the hyperparameter space to search:X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
Initialize the Grid Search object and specify the scoring metric (e.g., accuracy):param_grid = {'n_estimators': [10, 50, 100],'max_depth': [5, 8, 12]}
Perform grid search:grid_search = GridSearchCV(estimator=estimator,param_grid=param_grid,
cv=5,
scoring='accuracy')
Evaluate the best-performing model using the testing set:grid_result = grid_search.fit(X_train, y_train)
best_model = grid_result.best_estimator_y_pred = best_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Best Model Accuracy: {accuracy:.3f}")
Method 2: Randomized Search
Import necessary libraries:Load your dataset and split it into training and testing sets:import numpy as npfrom sklearn.model_selection import RandomizedSearchCV
from sklearn.metrics import accuracy_score
Define the hyperparameter space to search:X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
Initialize the Randomized Search object and specify the scoring metric (e.g., accuracy):param_random = {'n_estimators': [10, 50, 100],'max_depth': [5, 8, 12]}
Perform randomized search:random_search = RandomizedSearchCV(estimator=estimator,param_distributions=param_random,
cv=5,
scoring='accuracy',
n_iter=10)
Evaluate the best-performing model using the testing set:random_result = random_search.fit(X_train, y_train)
best_model = random_result.best_estimator_y_pred = best_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Best Model Accuracy: {accuracy:.3f}")
Conclusion
Hyperparameter tuning is an essential step in machine learning to find the optimal values for model parameters. Scikit-Learn provides two main methods for hyperparameter tuning: Grid Search and Randomized Search. By using these methods, you can efficiently explore the hyperparameter space and find the best-performing models for your datasets.
Remember to tune your hyperparameters carefully, as they can significantly impact the performance of your machine learning models!