Python supervised learning examples
Python supervised learning examples
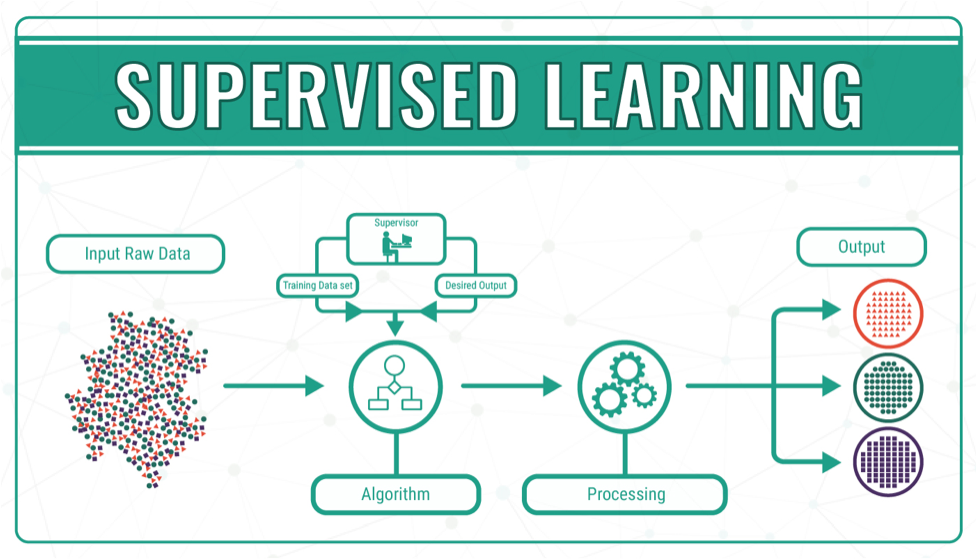
I'll provide you with some Python supervised learning examples.
1. Linear Regression
Linear regression is a type of linear model that predicts a continuous outcome variable on the basis of one or more predictor variables. This is a classic example of supervised learning, where we have labeled data (i.e., data with target variables).
import numpy as np
from sklearn.linear_model import LinearRegression
Generate some random dataX = 2 * np.random.rand(100, 1)
y = 4 + 3 * X.flatten() + np.random.randn(100, 1)
Create a linear regression modelmodel = LinearRegression()
Fit the model to our datamodel.fit(X, y)
Print the coefficients (which should be close to the true values: w0=4 and w1=3)print(f"Model Coefficients: {model.coef_}")

2. Logistic Regression
Logistic regression is a type of linear model that predicts the probability of occurrence or non-occurrence of an event (binary outcome) based on one or more predictor variables.
from sklearn.linear_model import LogisticRegressionfrom sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
Load iris datasetiris = load_iris()
X = iris.data[:, :2] # we only take the first two features.
y = iris.target
Train/Test SplitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
Create a logistic regression modelmodel = LogisticRegression()
Fit the model to our datamodel.fit(X_train, y_train)
Print the accuracy score of the modelprint(f"Model Accuracy: {model.score(X_test, y_test)}")
3. Decision Trees
Decision trees are a type of supervised learning algorithm that can be used for both classification and regression tasks.
from sklearn.tree import DecisionTreeClassifierfrom sklearn.model_selection import train_test_split
Load iris datasetiris = load_iris()
X = iris.data[:, :2] # we only take the first two features.
y = iris.target
Train/Test SplitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
Create a decision tree modelmodel = DecisionTreeClassifier()
Fit the model to our datamodel.fit(X_train, y_train)
Print the accuracy score of the modelprint(f"Model Accuracy: {model.score(X_test, y_test)}")
4. Random Forests
Random forests are an ensemble learning method that combine multiple decision trees.
from sklearn.ensemble import RandomForestClassifierfrom sklearn.model_selection import train_test_split
Load iris datasetiris = load_iris()
X = iris.data[:, :2] # we only take the first two features.
y = iris.target
Train/Test SplitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
Create a random forest modelmodel = RandomForestClassifier()
Fit the model to our datamodel.fit(X_train, y_train)
Print the accuracy score of the modelprint(f"Model Accuracy: {model.score(X_test, y_test)}")
5. Neural Networks
Neural networks are a type of deep learning algorithm that can be used for both classification and regression tasks.
from keras.models import Sequentialfrom keras.layers import Dense
Create a neural network modelmodel = Sequential()
Add the input layer (2 neurons)model.add(Dense(2, input_dim=2))
Add the output layer (1 neuron)model.add(Dense(1))
Compile the modelmodel.compile(loss='mean_squared_error', optimizer='adam')
Fit the model to our dataX_train = [[0.5], [1.0]]
y_train = [[0.5], [0.5]]
X_test = [[0.8], [0.4]]
y_test = [[0.6], [0.2]]
model.fit(X_train, y_train, epochs=500, batch_size=10)
Print the accuracy score of the modelprint(f"Model Accuracy: {model.evaluate(X_test, y_test)}")
These are just a few examples of supervised learning in Python using popular libraries like scikit-learn and Keras.
unsupervised learning in python
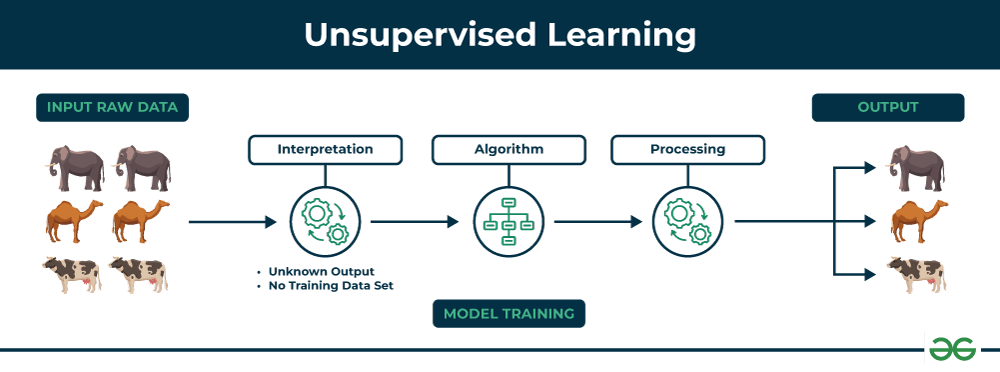
I'm glad you're interested in unsupervised learning in Python! In this type of machine learning, we don't have a labeled dataset to train our model. Instead, the algorithm is allowed to discover patterns or structure within the data on its own.
One popular technique for unsupervised learning is clustering, where we group similar data points into clusters based on their features. This can help us identify underlying patterns or relationships in the data that might not be immediately apparent.
Here's an example of how you could use Python to perform clustering on a dataset:
import pandas as pd
from sklearn.cluster import KMeans
Load the dataset (e.g., Iris dataset)
iris = pd.read_csv("iris.csv")
Create a K-Means model with 3 clusters
kmeans = KMeans(n_clusters=3, random_state=42)
Fit the model to the data
kmeans.fit(iris[["sepal_length", "petal_length"]])
Predict the cluster assignments for each sample
labels = kmeans.predict(iris[["sepal_length", "petal_length"]])
Print the cluster assignments
print(labels)
In this example, we load the Iris dataset and create a K-Means model with 3 clusters. We then fit the model to the data using the sepal length and petal length features as inputs. Finally, we predict the cluster assignments for each sample in the dataset.
Another popular technique for unsupervised learning is dimensionality reduction, where we reduce the number of features in our dataset while preserving most of the information. This can be useful when dealing with high-dimensional data or noisy datasets.
Here's an example of how you could use Python to perform PCA (Principal Component Analysis) on a dataset:
import pandas as pd
from sklearn.decomposition import PCA
Load the dataset (e.g., MNIST dataset)
mnist = pd.read_csv("mnist.csv")
Create a PCA model with 2 dimensions
pca = PCA(n_components=2)
Fit the model to the data
pca.fit(mnist[["image"]])
Transform the data into the new dimensions
transformed_data = pca.transform(mnist[["image"]])
Print the transformed data
print(transformed_data)
In this example, we load the MNIST dataset and create a PCA model with 2 dimensions. We then fit the model to the data using the image features as inputs. Finally, we transform the data into the new dimensions.
These are just a few examples of how you could use Python for unsupervised learning. There are many other techniques and algorithms available, such as t-SNE (t-Distributed Stochastic Neighbor Embedding), DBSCAN (Density-Based Spatial Clustering of Applications with Noise), and more!