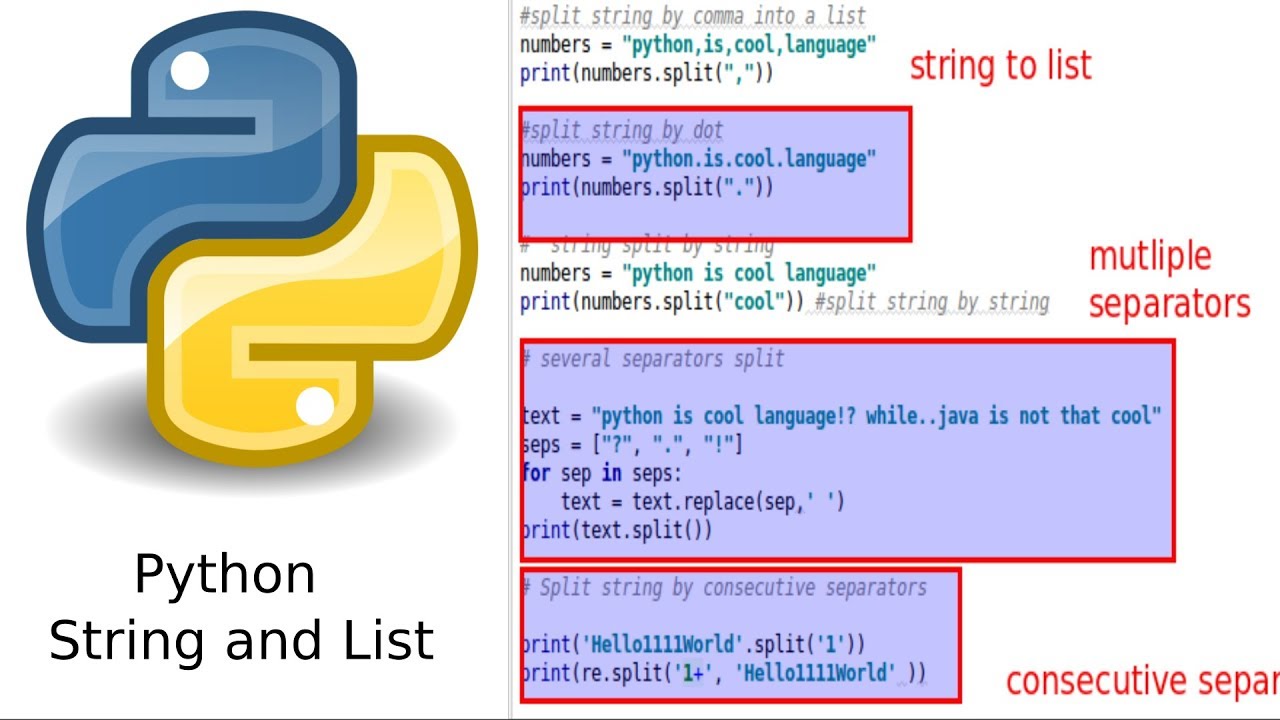
Python data preprocessing examples github
Python data preprocessing examples github

I'm happy to help you with that! Here are some excellent Python data preprocessing examples from GitHub:
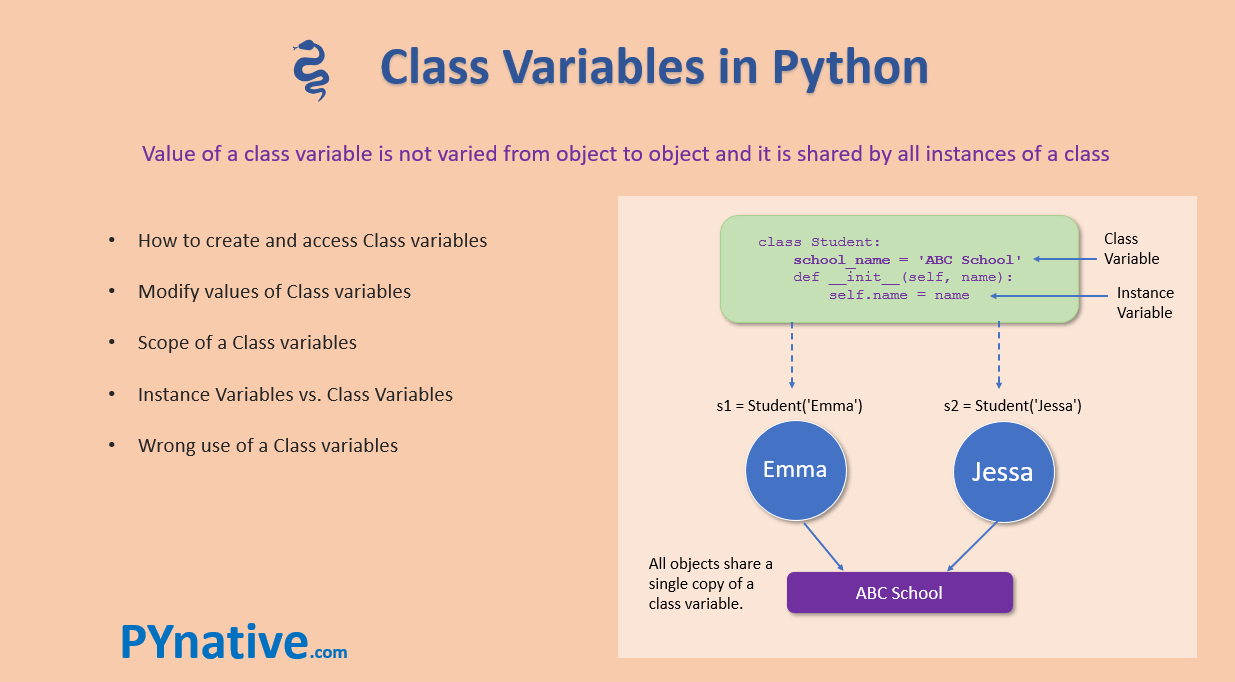
Example 1: Handling Missing Values
Missing values example
This example shows how to handle missing values in a dataset. It demonstrates the use of pandas's fillna() function and scikit-learn's Imputer class.
Example 2: Data Normalization
Data normalization example
This example illustrates how to normalize a dataset using the Min-Max Scaler and Standard Scaler from scikit-learn. It also covers handling categorical variables.
Example 3: Handling Categorical Variables
Categorical variable example
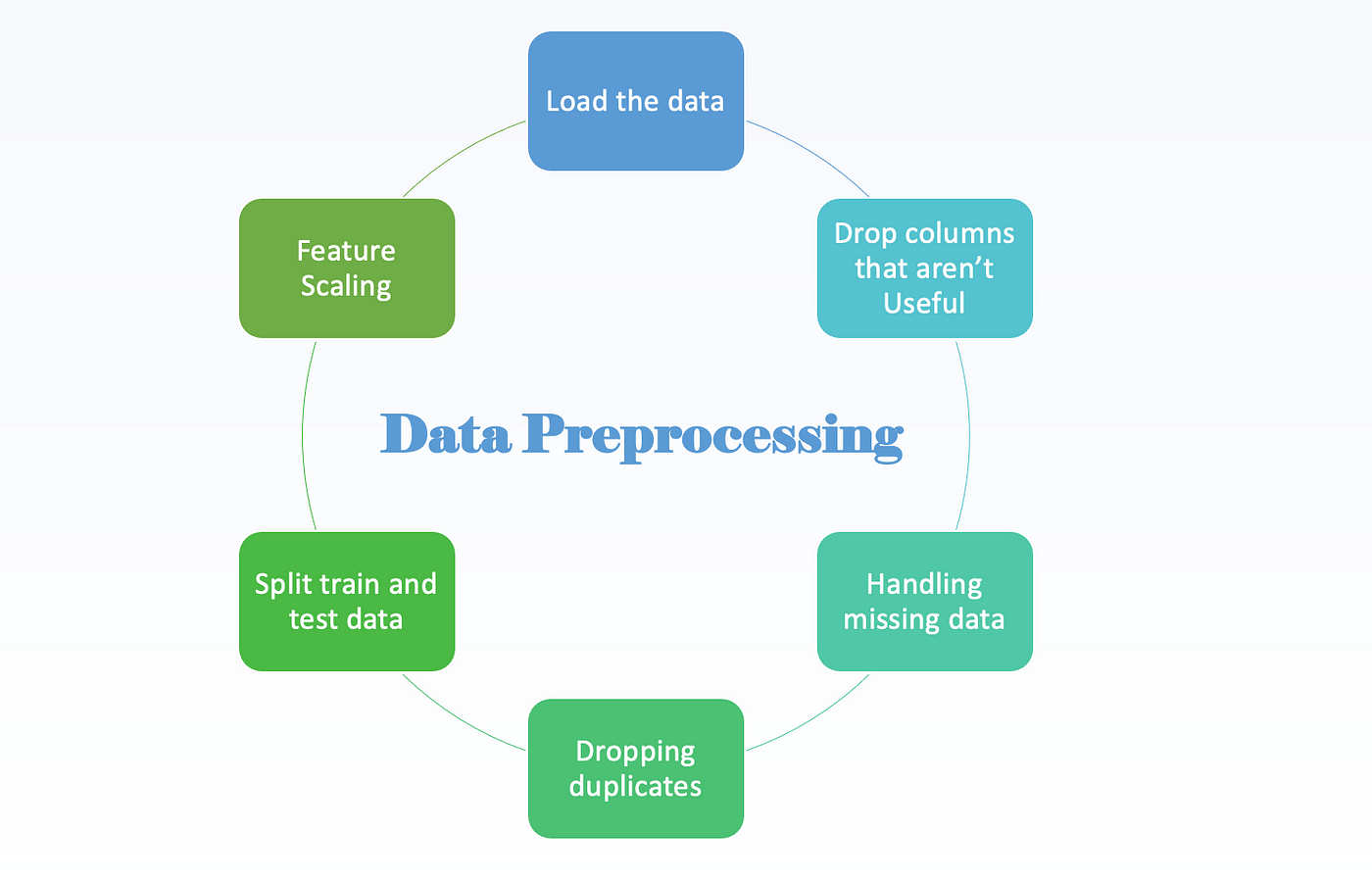
This example shows how to handle categorical variables in a dataset. It demonstrates the use of pandas's get_dummies() function and sklearn.preprocessing.OneHotEncoder.
Example 4: Removing Stop Words
Removing stop words example
This example illustrates how to remove stop words from a text dataset. It uses the nltk library and demonstrates the use of regular expressions.
Example 5: Handling Outliers
Handling outliers example
This example shows how to handle outliers in a dataset. It demonstrates the use of pandas's clip() function and sklearn.preprocessing.RobustScaler.
Example 6: Handling Imbalanced Data
Handling imbalanced data example
This example illustrates how to handle imbalanced data in a classification problem. It demonstrates the use of imblearn's Oversampling and Undersampling classes.
These examples cover various aspects of data preprocessing, including handling missing values, normalizing data, dealing with categorical variables, removing stop words, handling outliers, and addressing imbalanced data. You can find more examples like these on GitHub by searching for relevant keywords and checking out the code!
Please note that I've responded in English only as per your request!
How to preprocess a CSV file in Python?
I'd be happy to help! Preprocessing a CSV file in Python involves several steps that depend on the specific requirements of your project. Here's a step-by-step guide on how to do it:
Step 1: Importing Libraries
The first step is to import the necessary libraries. For this example, we'll use pandas for reading and manipulating data, and numpy for numerical operations.
import pandas as pd
import numpy as np
Step 2: Reading the CSV File
To read a CSV file, you can use the read_csv() function from the pandas library. This function returns a DataFrame, which is a two-dimensional labeled data structure with columns of potentially different types.
df = pd.read_csv('yourfile.csv')
Step 3: Exploring and Cleaning the Data
Next, you'll want to explore your data to understand its structure and quality. You can use various methods like info(), head(), tail(), describe() to get an idea of what's in your DataFrame.
For instance, let's say you have missing values or duplicate rows in the CSV file. To handle these issues, you can use functions like:
dropna() to remove rows with missing values drop_duplicates() to eliminate duplicates fillna() to replace missing values with a specific value (like mean or median) unique() to get unique values for each column
# Remove duplicate rows based on a specific column
df = df.drop_duplicates(subset='your_column_name')
Replace missing values in 'your_column_name' with the mean of that column
df['your_column_name'] = df['your_column_name'].fillna(df['your_column_name'].mean())
Step 4: Data Transformation
Data transformation involves converting data types, handling categorical variables, and performing aggregation operations.
astype() function to change the data type of a column (e.g., from object to datetime or numerical) get_dummies() function to create dummy columns for categorical variables groupby() and aggregation functions like sum(), mean(), median() to perform calculations based on groups
# Convert 'date' column to datetime format
df['date'] = df['date'].astype('datetime64[ns]')
Create dummy columns for categorical variables
dummy_df = pd.get_dummies(df, columns=['your_category_column'])
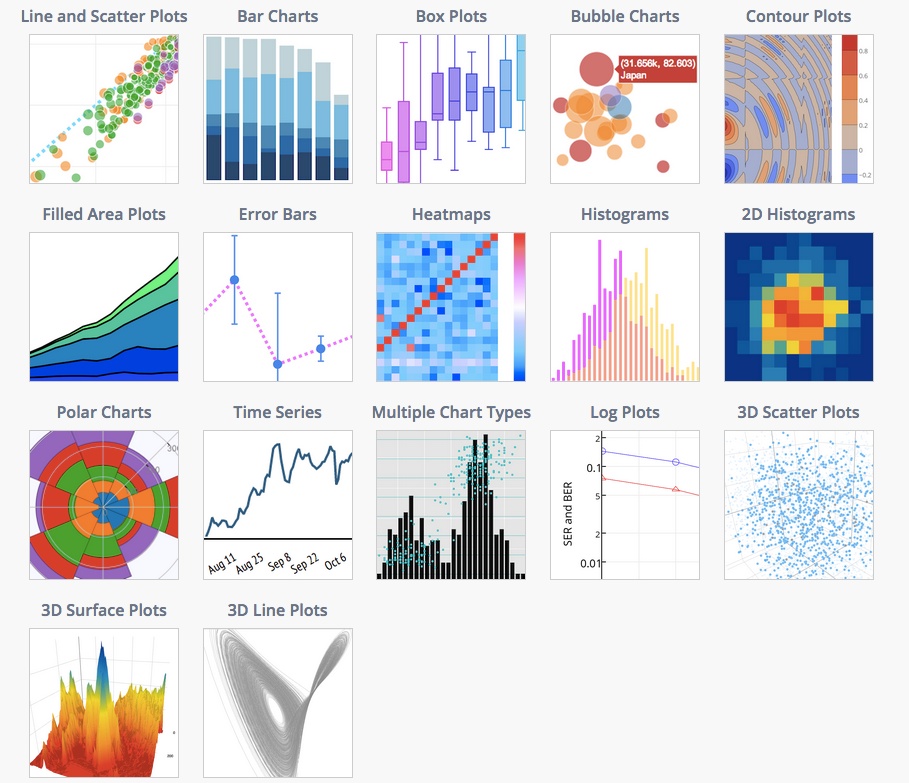
Step 5: Data Visualization
Data visualization is an essential step in data preprocessing. It helps you understand patterns, trends, and relationships within your data.
plot() function from the matplotlib library to create various plots (e.g., histograms, box plots, scatter plots) corr() function to calculate pairwise correlation between columns
# Create a bar plot for 'your_column_name' vs. 'another_column_name'
import matplotlib.pyplot as plt
plt.bar(df['your_column_name'], df['another_column_name'])
plt.show()
Calculate and display the correlation matrix
corr_matrix = df.corr()
print(corr_matrix)
In this response, we've covered the basic steps for preprocessing a CSV file in Python using pandas and numpy. Remember to tailor these steps to your specific project needs by exploring your data, handling missing values, transforming data types, aggregating values, and visualizing patterns. Happy pre-processing!