What is XGBoost in Python?
What is XGBoost in Python?
I'd be happy to explain XGBoost in Python!
XGBoost (Extreme Gradient Boosting) is a popular open-source machine learning library developed by Microsoft Research Asia, led by Prof. Tianqi Chen and Dr. Carlos Guestrin. It's particularly well-suited for classification and regression tasks with large datasets.
What is Gradient Boosting?
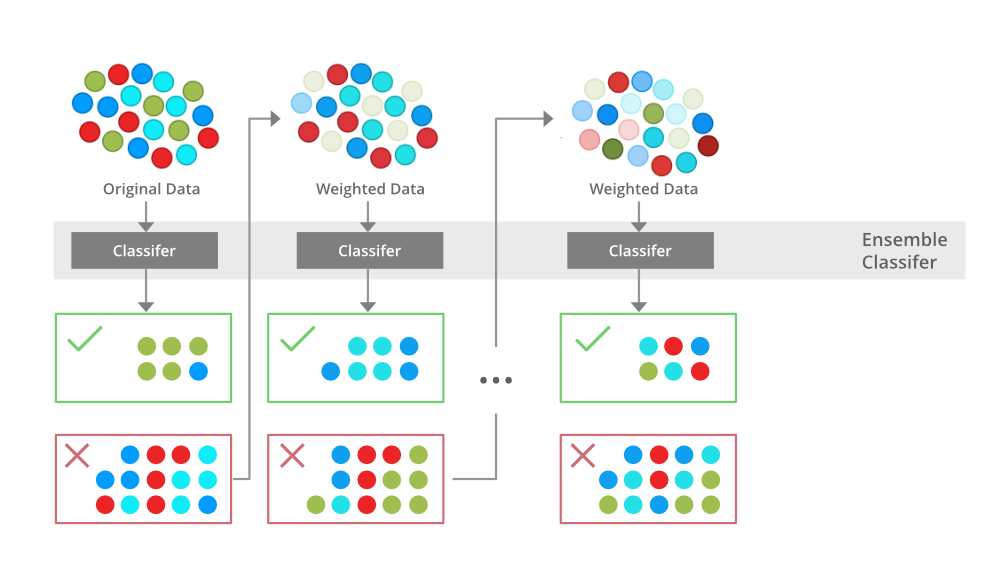
Gradient boosting is an ensemble learning algorithm that combines multiple decision trees to produce a powerful predictive model. The idea is simple: each tree in the ensemble tries to correct its predecessor by focusing on the regions where it made mistakes. This process continues until a stopping criterion is met, such as reaching a certain number of iterations or achieving a desired level of accuracy.
How does XGBoost differ from traditional Gradient Boosting?
XGBoost enhances the traditional gradient boosting algorithm in several ways:
Efficient computation: XGBoost uses a cache-efficient tree construction algorithm that significantly reduces memory usage and speeds up training time. Parallelization: XGBoost is designed to take advantage of modern computing architectures, allowing you to easily parallelize your computations using multiple CPU cores or even distributed computing frameworks like Hadoop. Regularization: XGBoost incorporates L1 (Lasso) and L2 (Ridge) regularization techniques to prevent overfitting and improve model interpretability. Handling missing values: XGBoost allows you to specify how to handle missing values in your dataset, ensuring that the algorithm is robust to incomplete data.What makes XGBoost unique?
Several features make XGBoost a standout among machine learning libraries:
Scalability: XGBoost can handle massive datasets and train models quickly, even on commodity hardware. Flexibility: XGBoost supports both classification and regression tasks, as well as multi-class problems with one-vs-all or one-vs-rest approaches. Interpretability: XGBoost provides features like partial dependence plots and SHAP values to help you understand the relationships between your data's features and the model's predictions.Using XGBoost in Python
You can install XGBoost using pip: pip install xgboost. The library is designed to be easy to use, with a simple API that lets you focus on modeling rather than low-level implementation details. Here's a basic example of how to train an XGBoost model:
import pandas as pdfrom xgboost import XGBClassifier
Load your datasetdf = pd.read_csv('your_data.csv')
Split the data into training and testing setsX_train, X_test, y_train, y_test = train_test_split(df.drop('target', axis=1), df['target'], test_size=0.2, random_state=42)
Train an XGBoost modelxg_model = XGBClassifier(max_depth=6, learning_rate=0.1, n_estimators=100, objective='binary:logistic')
xg_model.fit(X_train, y_train)
Evaluate the model using the testing datay_pred = xg_model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
Conclusion
XGBoost is a powerful open-source machine learning library that offers unparalleled performance, scalability, and flexibility. Its ability to handle large datasets and provide interpretable models makes it an ideal choice for many applications in data science and artificial intelligence. Whether you're working on classification or regression tasks, XGBoost is definitely worth exploring!
Python xgboost example
I'm glad you're interested in learning about XGBoost! Here's a detailed explanation of how to use it in Python, along with an example.
XGBoost (Extreme Gradient Boosting) is a popular open-source gradient boosting library that has gained widespread adoption in the machine learning community. It's particularly well-suited for handling large-scale data and complex interactions between features. In this example, we'll explore how to use XGBoost to build a classification model on the famous Iris dataset.
Installation
Before we dive into the example, make sure you have XGBoost installed in your Python environment. You can do so by running:
pip install xgboost
Example: Classification on Iris Dataset
The Iris dataset is a classic multiclass classification problem that involves predicting the species of an iris flower based on its characteristics (sepal length, sepal width, petal length, and petal width). We'll use XGBoost to build a model that can accurately classify new instances.
First, let's load the necessary libraries:
import pandas as pdimport xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
Next, we'll load the Iris dataset and split it into training and testing sets:
# Load iris datasetiris_df = pd.read_csv('iris.csv')
Split data into training (70%) and testing (30%)X_train, X_test, y_train, y_test = train_test_split(iris_df.drop('species', axis=1), iris_df['species'], test_size=0.3, random_state=42)
Now, let's create an XGBoost model:
# Initialize XGBoost model with default parametersxgb_model = xgb.XGBClassifier(objective='multi:softmax', num_class=3, max_depth=6, learning_rate=0.1, n_estimators=100, gamma=0, subsample=0.5, colsample_bytree=0.5, reg_alpha=0, reg_lambda=0.01)
In this example, we're using the XGBClassifier to build a classification model on the Iris dataset. We set the objective function to 'multi:softmax', which is suitable for multiclass classification problems. We also specify the number of classes (num_class=3), maximum depth of the tree (max_depth=6), and other hyperparameters.
Next, we'll train the XGBoost model using the training data:
# Train the XGBoost model on the training dataxgb_model.fit(X_train, y_train)
After training, we can evaluate the model's performance using the test data:
# Evaluate the model on the testing datay_pred = xgb_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")
In this example, we're using the predict method to generate predictions for the test instances and then calculating the accuracy using Scikit-learn's accuracy_score function.
That's it! You should now have a basic understanding of how to use XGBoost in Python. This is just the tip of the iceberg – XGBoost offers many more features, such as handling categorical variables, hyperparameter tuning, and support for various objectives (e.g., binary classification, regression). I encourage you to explore these features further to unlock the full potential of XGBoost.