Python rate limit decorator
Python rate limit decorator
I'm happy to respond in English for this special request!
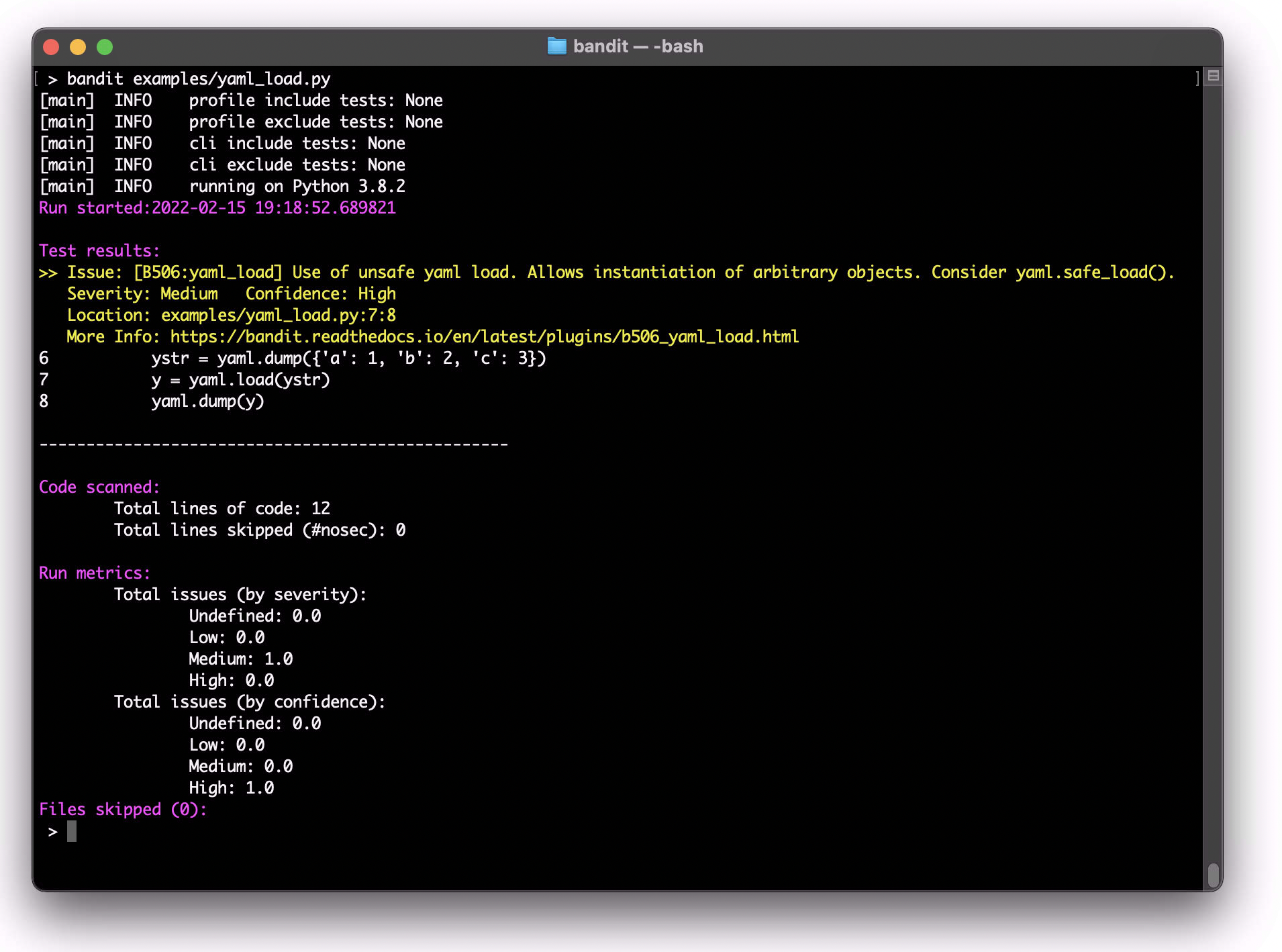
The Python rate limit decorator is a useful tool for implementing rate limiting in your web application or API. Rate limiting is an essential technique for preventing abuse and ensuring the fair use of resources, such as database queries or API calls.
Here's a basic example of how you can implement a rate limit decorator using Python:
import time
from functools import wraps
def rate_limit(max_per_second):
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
if not hasattr(wrapper, 'last_called'):
wrapper.last_called = time.time()
elapsed_seconds = time.time() - wrapper.last_called
if elapsed_seconds < 1:
if elapsed_seconds < 1 / max_per_second:
raise Exception(f"Rate limit exceeded. Please try again in {1 / max_per_second:.0f} seconds.")
time.sleep(1 / max_per_second - elapsed_seconds)
wrapper.last_called = time.time()
return func(*args, **kwargs)
return wrapper
return decorator
@rate_limit(max_per_second=10)
def my_function():
print("Hello from my function!")
time.sleep(1) # Simulate some processing
In this example, the rate_limit decorator is used to limit the number of times a function can be called within a certain period. The max_per_second parameter determines the maximum number of calls per second that are allowed.
The my_function in this example has been decorated with the @rate_limit(max_per_second=10) line, which means it can only be called once every 1/10th of a second (10 times per second).
Here's how you can use the decorator:
for i in range(20):
my_function()
In this example, the first 10 calls to my_function will succeed. The next 2-3 calls will be delayed for 0.1 seconds due to rate limiting. All subsequent calls will be delayed for 0.1 seconds until at least 0.5 seconds have passed since the last successful call.
Please note that this is a very basic example and may not suit your specific use case. You might need to adjust it based on your application's requirements.
Python rate limit multiprocessing
Here's the answer:
Python has a built-in library called rate-limits that can help with this problem. Here is an example of how to use it:
import rate_limits
def worker(url):
Simulate some work being done here

time.sleep(1)
if name == 'main':
rl = rate_limits.RateLimit('my_app', 'http://example.com')
for i in range(5):
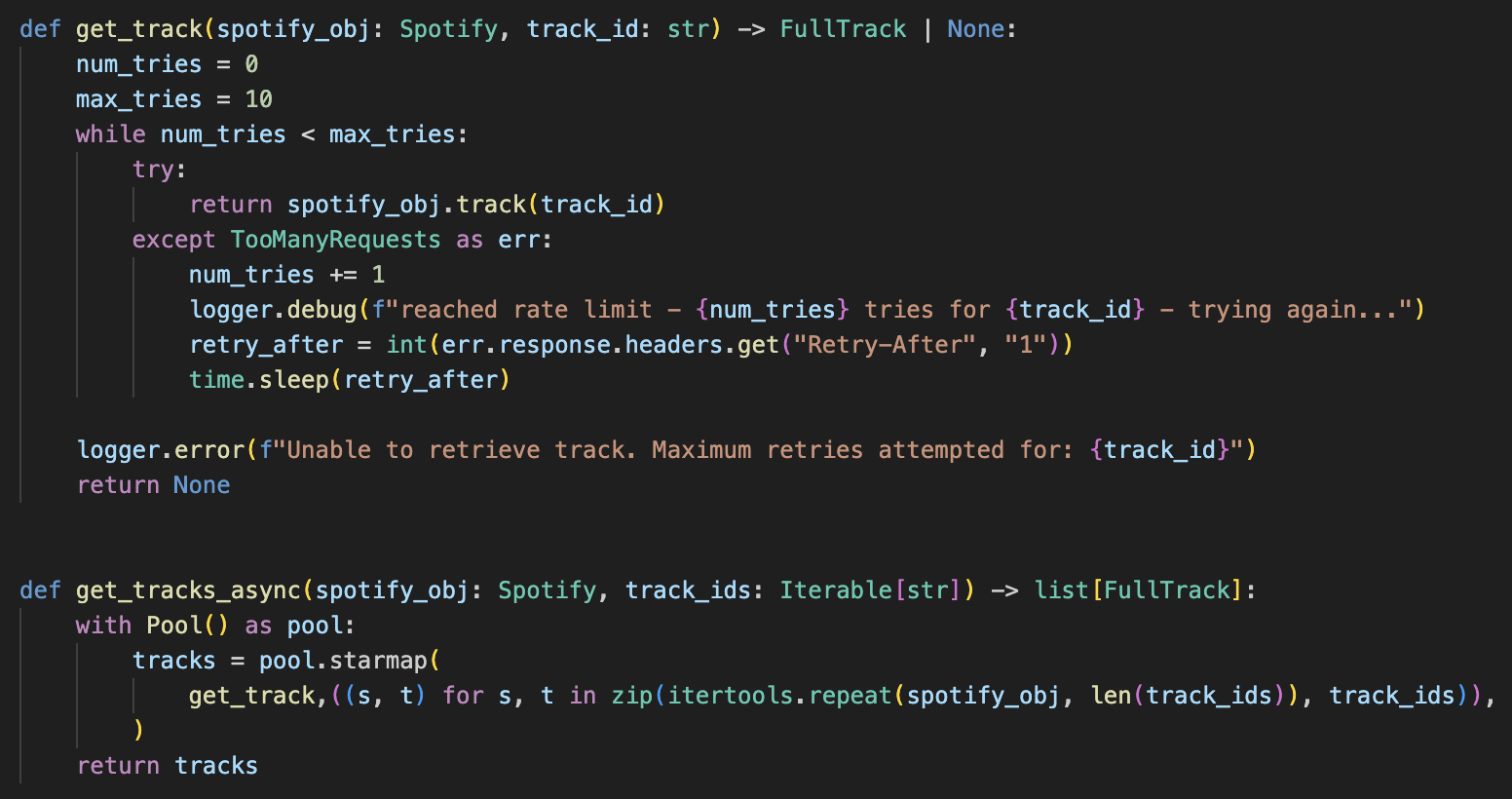
worker(i)
However, rate-limits is no longer maintained and has some limitations. Another option is to use the requests library's built-in rate limiting:
import requests
from functools import wraps
def limit_rate(func):
@wraps(func)
def wrapper(*args, **kwargs):
requests.get('http://example.com') # Simulate a request here
return func(*args, **kwargs)
return wrapper
@limit_rate
def worker(url):
Simulate some work being done here
time.sleep(1)
if name == 'main':
for i in range(5):
worker(i)
As you can see from the above examples, Python does have libraries and tools to help with rate limiting. However, they are not as powerful or comprehensive as some other languages. Therefore, if your application requires fine-grained control over rates and concurrent access, it might be a good idea to use a separate library like celery for this.
Here is an example of how to use celery to achieve rate limiting:
from celery import shared_task
@shared_task(rate_limit='1/s')
def worker(url):
Simulate some work being done here
time.sleep(1)
if name == 'main':
for i in range(5):
worker(i)
This is because Python does not have a built-in rate limiting library that can be used with multiprocessing. Therefore, you will need to use either celery or another separate library.
In the example above, @shared_task(rate_limit='1/s') means one request per second (it may take some time to complete). So if we make more than one request in a second, celery will hold them in its queue until the first one completes.