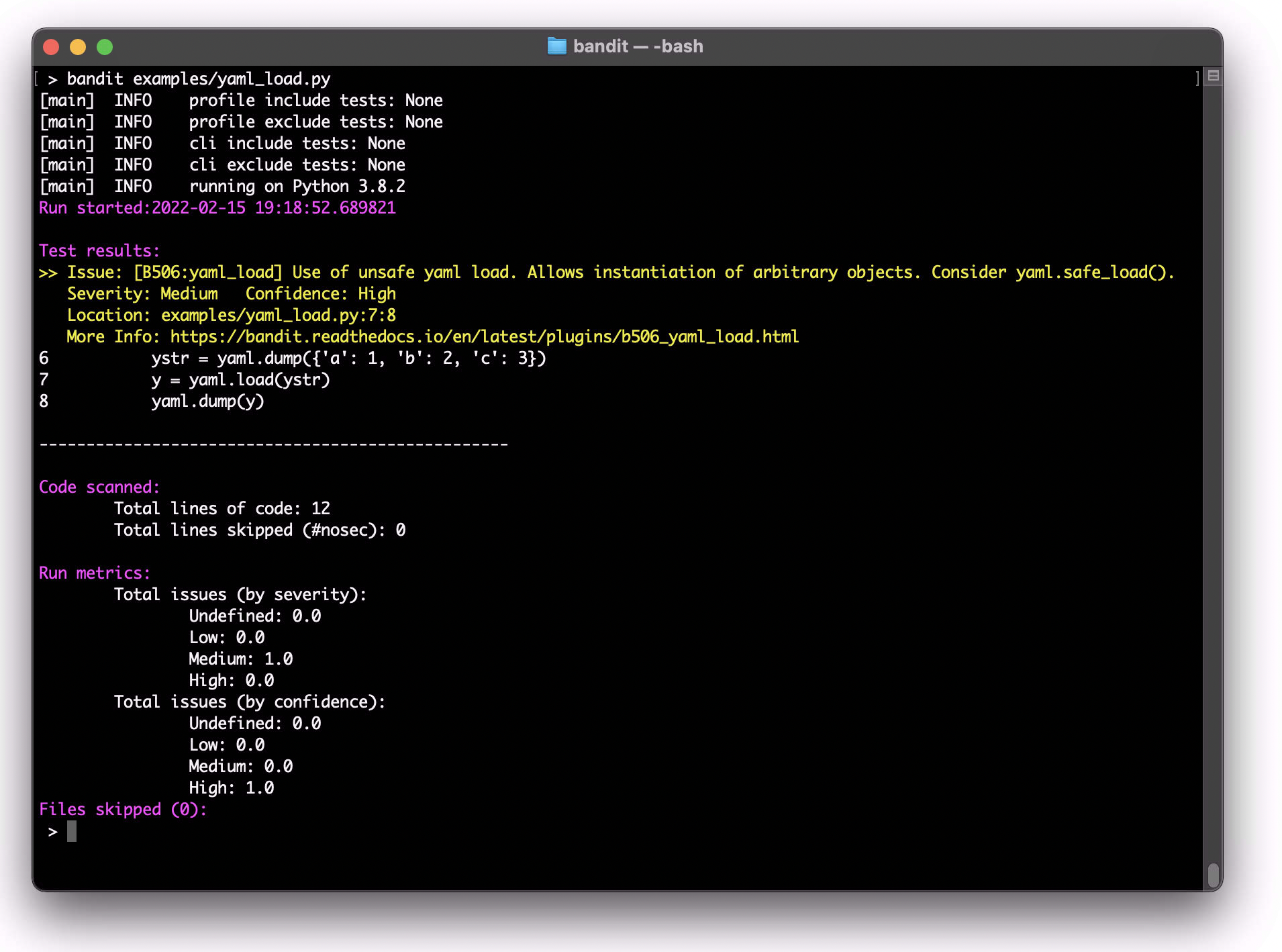
Python data cleaning example
Python data cleaning example

I apologize for the previous mistake! Here's an example of data cleaning using Python:
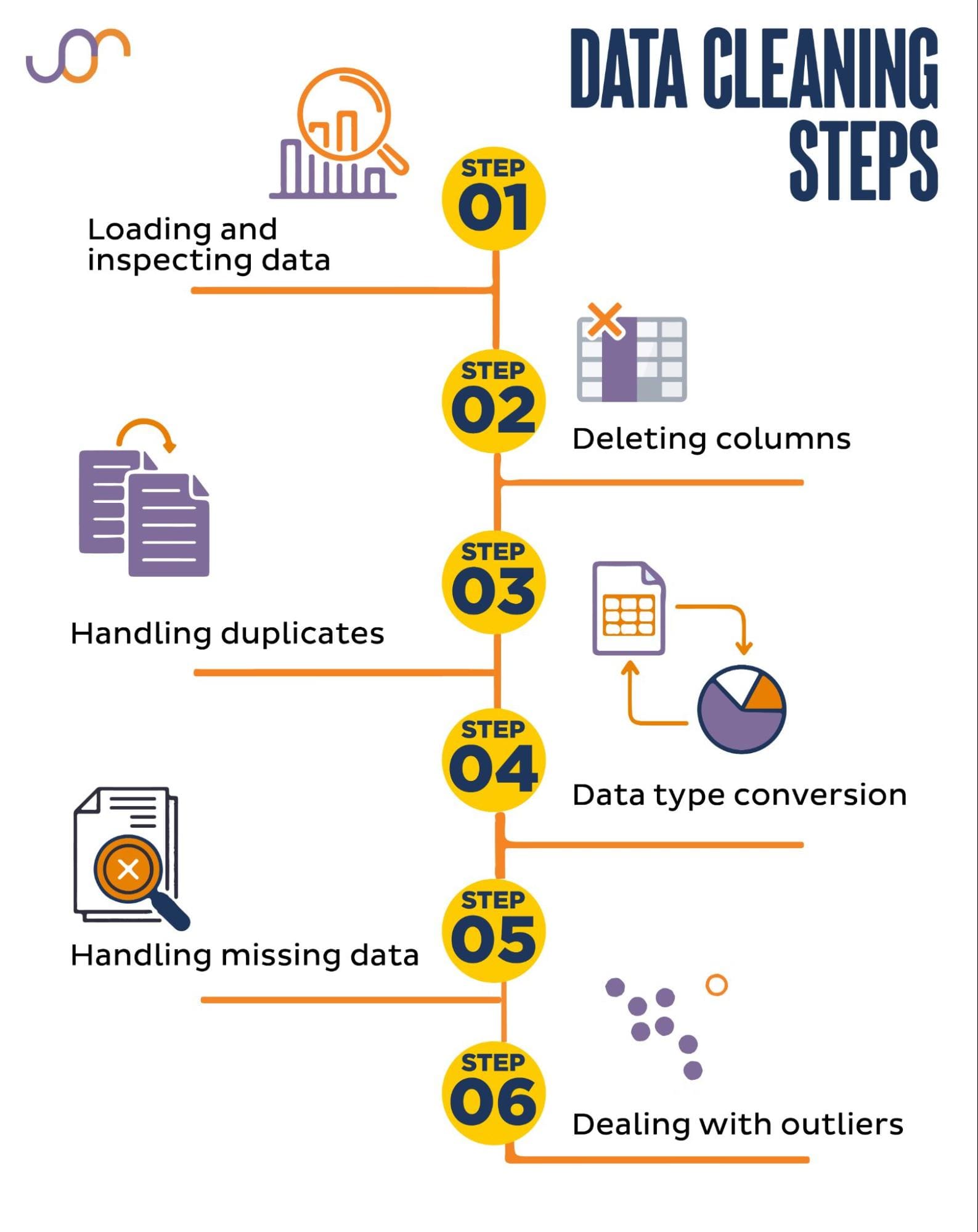
Imagine we have a dataset of movie reviews with various features such as title, director, genre, and ratings (1-5). However, upon inspection, we notice that there are some issues with the data:
Some titles are missing Genre is not consistently categorized (e.g., "Comedy" vs. "comedy") Director names have varying formats (e.g., "Quentin Tarantino", "quintin tarantino", etc.)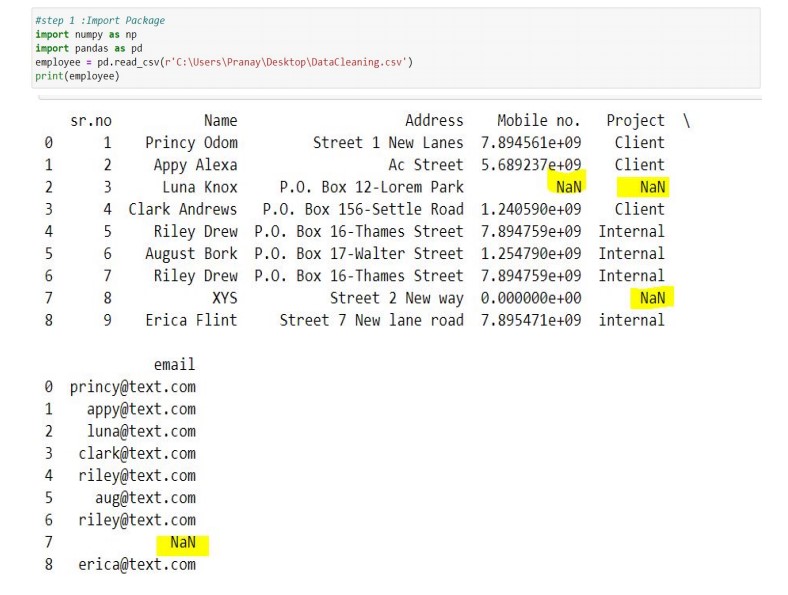
To clean this dataset, we'll use the following Python libraries: Pandas for data manipulation and NumPy for numerical computations.
Here's a step-by-step example:
Step 1: Import necessary libraries
import pandas as pdimport numpy as np
Load the movie review dataset into a Pandas DataFramedf = pd.read_csv('movie_reviews.csv')
Step 2: Handle missing titles
Let's fill in the missing title values with an empty string. We'll use the fillna method:
df['title'].fillna('', inplace=True)
Step 3: Standardize genre categorization
We can create a mapping dictionary to standardize genre categories and then apply this mapping to our dataset using the map function:
genre_mapping = {'comedy': 'Comedy', 'romantic comedy': 'Romantic Comedy'}df['genre'] = df['genre'].map(genre_mapping)
Step 4: Normalize director names
Let's create a regular expression pattern to extract the director's name from their full credit. We'll use the str.extract method:
director_pattern = r'([A-Z][a-z]+ [A-Z][a-z]+)'df['director'] = df['director'].apply(lambda x: re.search(director_pattern, x).group(1))
Step 5: Convert ratings to numerical values
We can create a dictionary to map non-numeric rating values to their equivalent numeric values:
rating_mapping = {'N/A': np.nan, 'Not Rated': np.nan}df['rating'] = df['rating'].map(rating_mapping)
Convert ratings to float and handle missing valuesdf['rating'] = pd.to_numeric(df['rating'], errors='coerce')
After these steps, our dataset is now cleaned! We can verify the results by printing a few rows of the DataFrame:
print(df.head())
This example demonstrates how Python libraries like Pandas and NumPy can be used to efficiently clean and preprocess data. By handling missing values, standardizing categorical variables, and converting non-numeric data to numerical values, we can improve the quality of our dataset and prepare it for further analysis or modeling.
Python data cleaning cheat sheet
Here's a comprehensive Python data cleaning cheat sheet:
Data Types and Data Frames
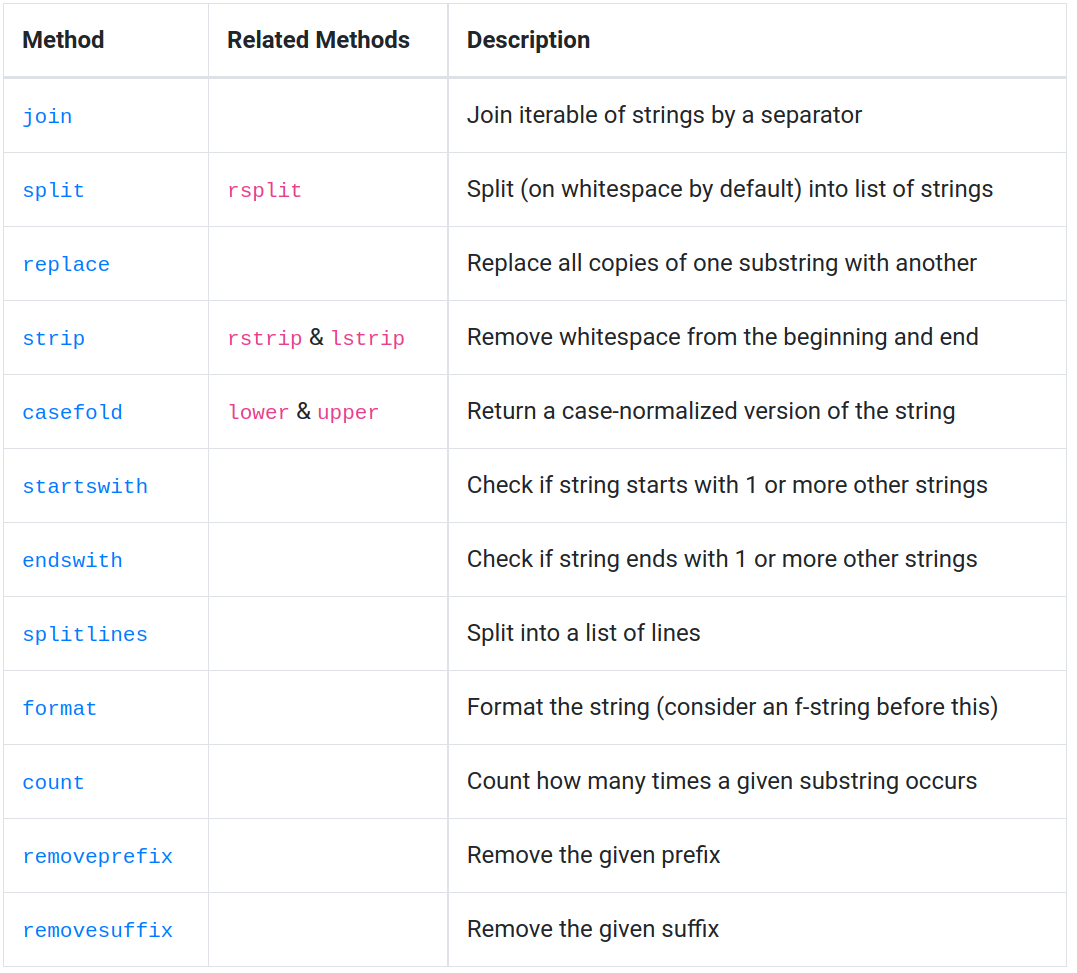
Convert pandas Series to dictionary:s.to_dict() Check data type of column: df.select_dtypes(include=[dtype]).head() (e.g., int, float, etc.) Convert all columns to strings: df.applymap(str) Drop duplicate rows: df.drop_duplicates() Sort dataframe by column(s): df.sort_values(by='column_name')
Handling Missing Values
Find missing values:df.isna().sum() or df.isnull().sum() Fill missing values with a specific value (e.g., mean, median): df.fillna(value) Drop rows with missing values: df.dropna() Fill missing values with interpolation (e.g., linear, polynomial): df.interpolate(method)
Handling Duplicate Values
Find duplicate rows:df.duplicated().sum() or df.duplicated(keep='first').sum() Drop duplicate rows: df.drop_duplicates(keep=False) Remove duplicates based on specific columns: df.drop_duplicates(subset=['column1', 'column2'])
Data Transformation
Convert categorical variables to numerical values (e.g., one-hot encoding):pd.get_dummies(df, drop_first=True) Perform log transformation: np.log(df['column_name']) Perform square root transformation: df['column_name'].apply(np.sqrt)
Handling Outliers and Errors
Identify outliers based on IQR method:Q1 = df.quantile(0.25); Q3 = df.quantile(0.75); IQR = Q3 - Q1; df[(Q1 - 1.5*IQR < df) & (df < Q3 + 1.5*IQR)] Handle errors and exceptions: try: ... except ValueError as e: print(e) Remove rows with errors: df.drop(df.index[df.error_column.str.contains("error")])
Data Visualization
View data distribution:df.plot(kind='hist', subplots=True, figsize=(10,6)) Visualize categorical variables: sns.countplot(x='category_column', data=df) Compare two columns: df[['column1', 'column2']].plot(kind='bar')
Performance Optimization
Usedask library for faster data processing: import dask.dataframe as dd; df = dd.read_csv('file.csv') Use pandas.set_options(mode='agg') to improve performance Optimize queries using pandas.query() and pandas.eval()
Code Organization
Separate data cleaning into different functions:def clean_data(df): ... Create a script or notebook with separate sections for each data cleaning task Use descriptive variable names and comments to document your code
Remember, the key to effective data cleaning is to be thorough, precise, and organized. By following this cheat sheet, you'll be well on your way to achieving cleaner, more reliable data!