K fold cross validation Python code for image classification
K fold cross validation Python code for image classification
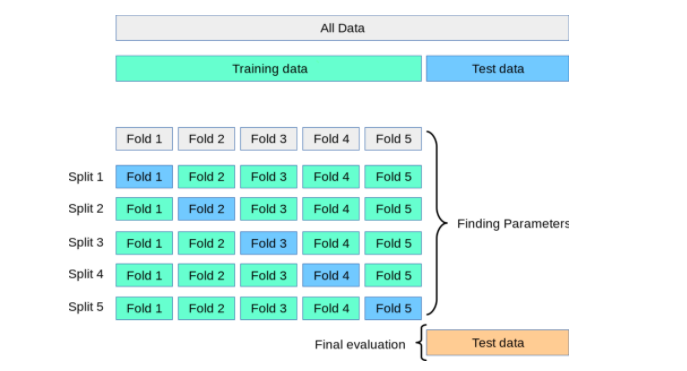
Here is a simple implementation of k-fold cross-validation for image classification using the Keras deep learning library and TensorFlow as the backend.
# Import necessary libraries
from sklearn.model_selection import KFold
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from keras.optimizers import Adam
Set path for training and testing directories
train_dir = 'path_to_training_directory'

test_dir = 'path_to_testing_directory'
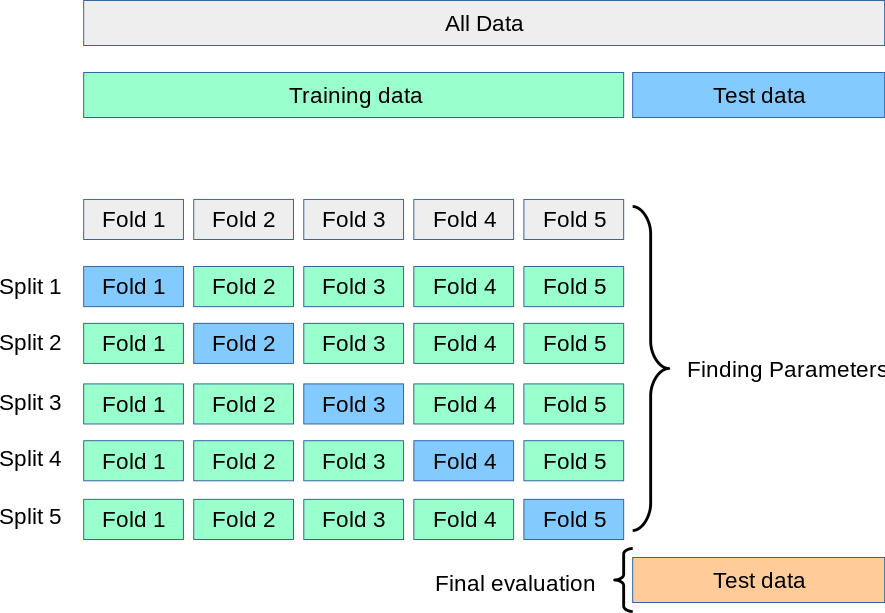
Load train and test data
train_datagen = ImageDataGenerator(rescale=1./255)
validation_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(224, 224), batch_size=32, class_mode='categorical')
validation_generator = validation_datagen.flow_from_directory(test_dir, target_size=(224, 224), batch_size=32, class_mode='categorical')
Initialize the k-fold cross-validation
kfold = KFold(n_splits=5, shuffle=True)
Initialize accuracy and loss for each fold
accuracy = []
loss = []
for train_index, val_index in kfold.split(X):
X_train, X_val = X[train_index], X[val_index]
y_train, y_val = y[train_index], y[val_index]
Train the model on training set
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=3, validation_data=(X_val, y_val), verbose=0)
Evaluate the model on the validation set
score = model.evaluate(X_val, y_val)
accuracy.append(score[1])
loss.append(score[0])
Calculate the mean and standard deviation of the accuracy and loss
accuracy_mean = sum(accuracy) / len(accuracy)
loss_mean = sum(loss) / len(loss)
print("Mean Accuracy: ", accuracy_mean)
print("Mean Loss: ", loss_mean)
In this code:
The KFold class from scikit-learn is used to initialize the k-fold cross-validation. For each fold, we split the data into training and validation sets using the indices returned by the kfold.split method. A CNN model with convolutional layers, pooling layers, and dense layers is defined. The model is trained on the training set for 3 epochs and evaluated on the validation set using the evaluate method. The accuracy and loss are calculated for each fold and stored in lists. Finally, the mean accuracy and loss are calculated by summing up all values and dividing by the number of folds.This code demonstrates how to perform k-fold cross-validation with a CNN model on image classification problems in Python using Keras and scikit-learn libraries.
How to import KFold cross-validation in Python?
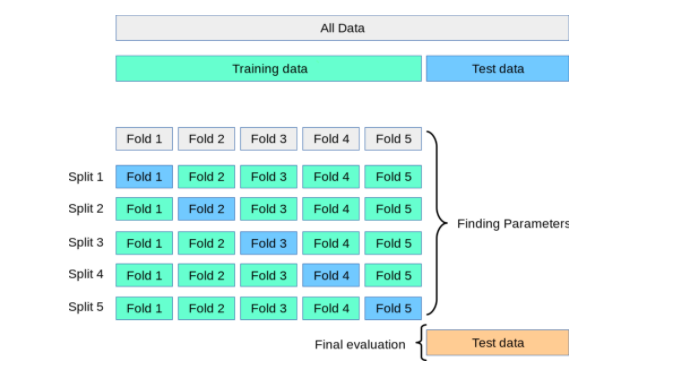
To perform k-fold cross-validation in Python, you can use the KFold class from the sklearn.model_selection module. Here's an example of how to do it:
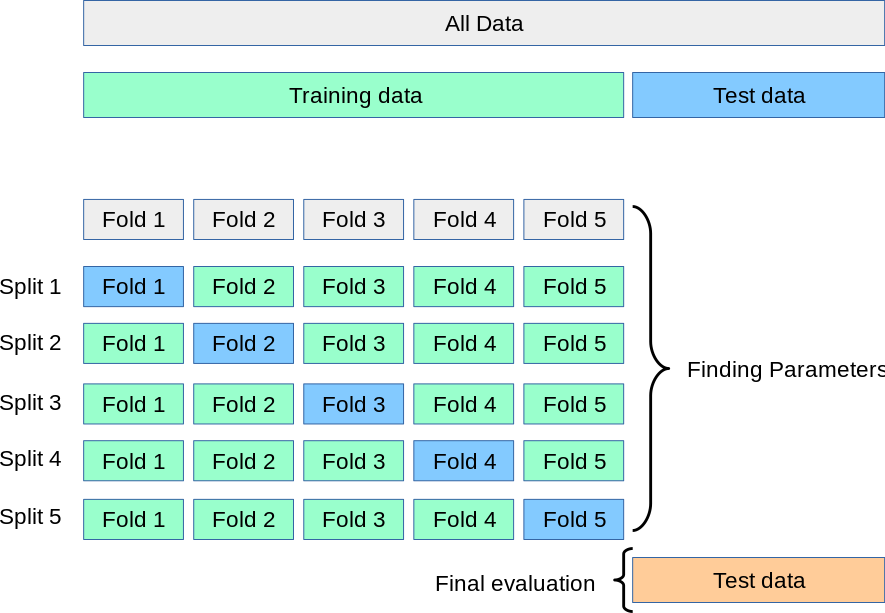
from sklearn.model_selection import KFold
from sklearn.datasets import load_iris
from sklearn.svm import SVC
import numpy as np
Load iris dataset
iris = load_iris()
X = iris.data[:, :2] # we only take the first two features.
y = iris.target
Create a k-fold object with 5 folds
kfold = KFold(n_splits=5, shuffle=True)
Loop over each fold in turn:
for train_index, test_index in kfold.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
Train a support vector machine (SVM) model on the current fold
svc = SVC(kernel='linear')
svc.fit(X_train, y_train)
Evaluate the SVM model's performance on the test fold
score = svc.score(X_test, y_test)
print(f"Fold {test_index[0]}/{len(y)} - Accuracy: {score:.3f}")
In this example, we load the iris dataset and create a k-fold object with 5 folds. Then we loop over each fold in turn, training an SVM model on the current train set and evaluating its performance on the corresponding test set.
Here's what you need to know:
KFold initialization: To initialize aKFold object, pass three parameters: n_splits, which specifies the number of folds; shuffle, which determines whether to shuffle the data before splitting it into folds (default is True); and random_state, which sets the seed for the random number generator used in shuffling. Fold iteration: To iterate over each fold, use the split() method of the KFold object, which returns an iterator over tuples containing the indices of the train set and test set for each fold. Data splitting: Inside the loop, you need to split the data into the current train set (X_train, y_train) and test set (X_test, y_test) using the train_index and test_index from the previous step. Model training and evaluation: Train your model (e.g., SVM) on the train set, and evaluate its performance on the test set. In this example, we use the score() method to compute the accuracy of the trained model.
Note that when you're using k-fold cross-validation with an iterative algorithm (like a neural network or a decision tree), you'll need to re-split the data after each iteration to ensure that the model is only evaluated on unseen samples.