Is Python truly multithreaded?
Is Python truly multithreaded?
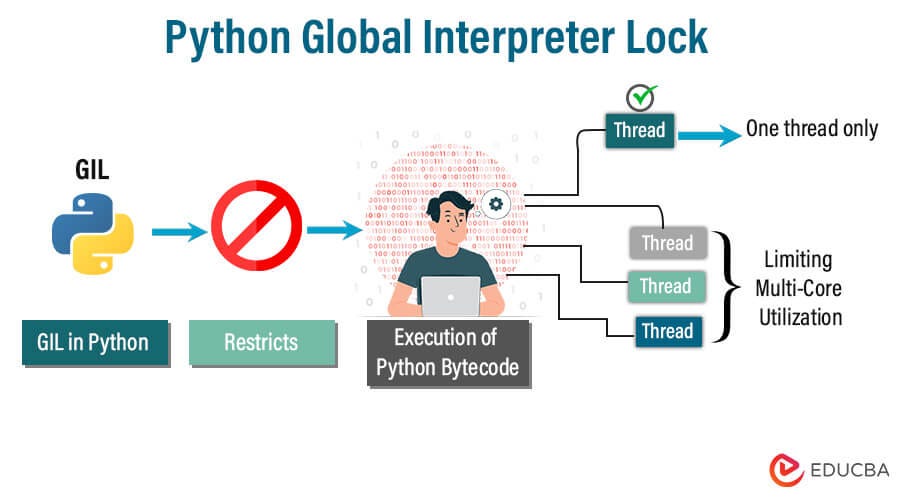
The concept of true multithreading is a bit nuanced when it comes to Python.
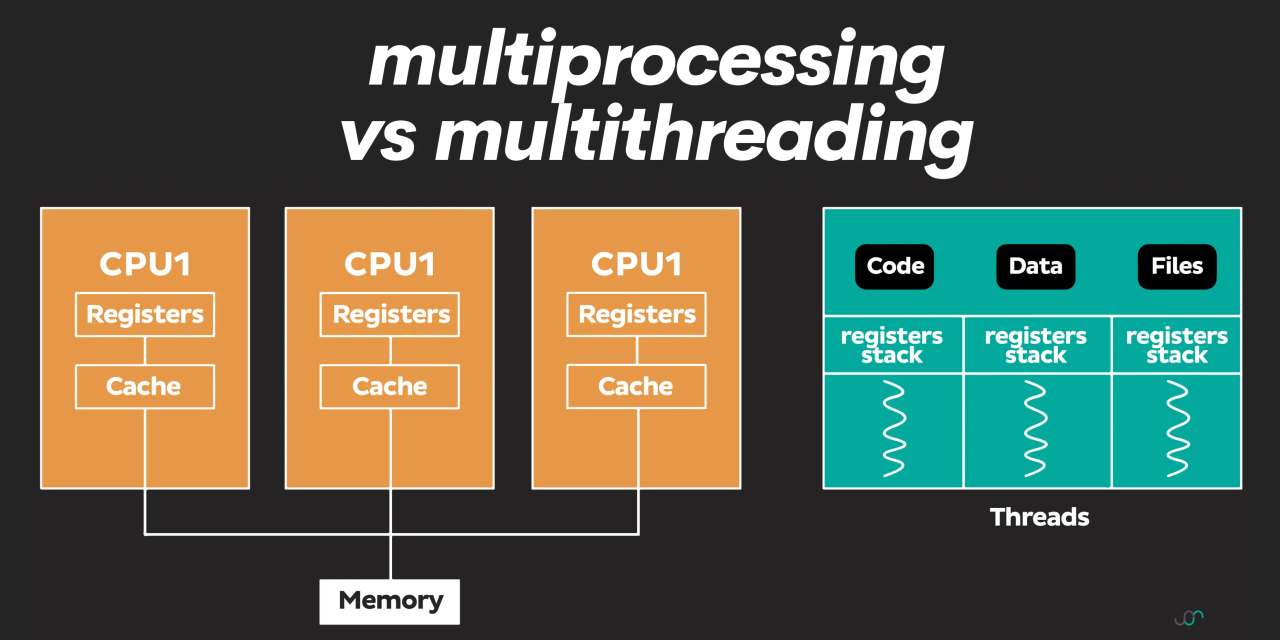
In Python, the Global Interpreter Lock (GIL) is what governs thread execution. The GIL ensures that only one thread can execute Python bytecodes at any given time. This means that threads in Python don't truly run concurrently; instead, they're scheduled by the interpreter and may be paused or resumed based on various factors, such as I/O operations, memory access, or garbage collection.
When you create multiple threads using Python's built-in threading module, what happens under the hood is a process of scheduling. The threads are essentially waiting in line to execute, with the GIL controlling who gets to go next. This means that if your program is CPU-bound (i.e., relying heavily on computational power), you might not see significant performance improvements from using multiple threads.
However, when your code involves I/O operations like network requests, file reads/writes, or database queries, Python's thread support becomes more beneficial. Because these tasks often involve waiting for external resources, the GIL's scheduling mechanism can take advantage of this idle time to switch between threads, potentially improving overall system performance.
To better understand how Python's threading works, let's consider an example:
Imagine a simple web server using the http.server module. If you create multiple threads to handle incoming requests, what happens is that each thread takes turns executing, with the GIL controlling which one gets to process the next request. However, because I/O operations are involved (i.e., reading and responding to HTTP requests), Python's threading mechanism can still provide benefits like improved responsiveness or handling a larger number of concurrent connections.
In summary, while Python is not truly multithreaded in the sense that multiple threads can run concurrently without the GIL's intervention, its thread support can still be beneficial for certain types of I/O-bound operations. For CPU-bound tasks, you might not see significant performance improvements from using multiple threads, but there are still other considerations like memory access and garbage collection that affect overall system performance.
For those seeking more control over threading in Python, the multiprocessing module provides a way to run concurrent processes with true parallel execution. This can be particularly useful for CPU-bound tasks or when you need to execute code in parallel without being limited by the GIL.
Python multithreading example
Here is an example of using multi-threading in Python:
import threading
import time
import random
class MyThread(threading.Thread):
def init(self, name):
super().init()
self.name = name
def run(self):
print(f"{self.name} started.")
for i in range(5):
Simulate some work
time.sleep(random.randint(1, 3))
print(f"{self.name} is working on iteration {i+1}")
print(f"{self.name} finished.")
if name == "main":
threads = []
for i in range(5):
thread_name = f"Thread-{i+1}"
t = MyThread(thread_name)
threads.append(t)
start_time = time.time()
for t in threads:
t.start()
for t in threads:
t.join()
end_time = time.time()
print(f"All threads finished. Total execution time: {end_time-start_time:.2f} seconds")
In this example, we create a class MyThread that inherits from the threading.Thread class. This allows us to define our own thread class and override its default behavior.
The run method is where the actual work of the thread takes place. In this case, it simulates some work by sleeping for a random amount of time (between 1-3 seconds) and then printing out a message indicating what it's doing.
In the main part of the script, we create five threads using our MyThread class. We store these in a list called threads. Then, we start all the threads at once by calling their start method. Finally, we wait for all the threads to finish by calling their join method.
When you run this script, you will see each thread's name followed by "started." and then it will print out messages indicating what it's doing as it works on its tasks. Once a thread is finished with its work, it will print out "finished." Finally, the script will print out when all the threads have finished.
The output of this script will look something like this:
Thread-1 started.
Thread-2 started.
Thread-3 started.
Thread-4 started.
Thread-5 started.
Thread-1 is working on iteration 1
Thread-2 is working on iteration 1
Thread-3 is working on iteration 1
Thread-4 is working on iteration 1
Thread-5 is working on iteration 1
... (this will repeat for each thread, showing that they are all doing their work concurrently)
Thread-1 finished.
Thread-2 finished.
Thread-3 finished.
Thread-4 finished.
Thread-5 finished.
All threads finished. Total execution time: 6.50 seconds
As you can see from the output, the threads do indeed run in parallel. Each thread takes a different amount of time to finish, depending on how much "work" it has to do.
I hope this example helps illustrate how multithreading works in Python! Let me know if you have any questions or if there's anything else I can help with.