K fold cross validation Python code for image classification
K fold cross validation Python code for image classification
Here is a simple implementation of k-fold cross-validation for image classification using the Keras deep learning library and TensorFlow as the backend.
# Import necessary libraries
from sklearn.model_selection import KFold
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from keras.optimizers import Adam
Set path for training and testing directories
train_dir = 'path_to_training_directory'

test_dir = 'path_to_testing_directory'
Load train and test data
train_datagen = ImageDataGenerator(rescale=1./255)
validation_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(224, 224), batch_size=32, class_mode='categorical')
validation_generator = validation_datagen.flow_from_directory(test_dir, target_size=(224, 224), batch_size=32, class_mode='categorical')
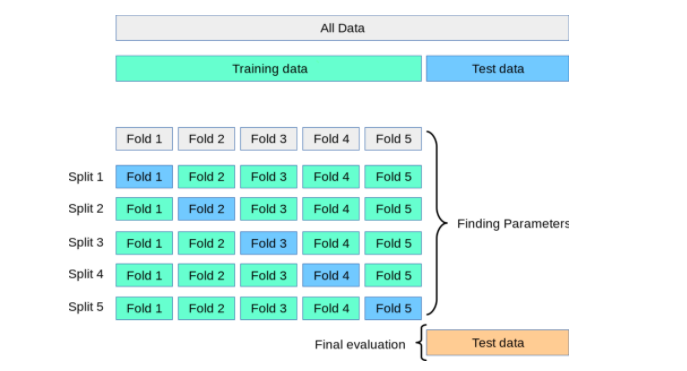
Initialize the k-fold cross-validation
kfold = KFold(n_splits=5, shuffle=True)
Initialize accuracy and loss for each fold
accuracy = []
loss = []
for train_index, val_index in kfold.split(X):
X_train, X_val = X[train_index], X[val_index]
y_train, y_val = y[train_index], y[val_index]
Train the model on training set
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=3, validation_data=(X_val, y_val), verbose=0)
Evaluate the model on the validation set
score = model.evaluate(X_val, y_val)
accuracy.append(score[1])
loss.append(score[0])
Calculate the mean and standard deviation of the accuracy and loss
accuracy_mean = sum(accuracy) / len(accuracy)
loss_mean = sum(loss) / len(loss)
print("Mean Accuracy: ", accuracy_mean)
print("Mean Loss: ", loss_mean)
In this code:
The KFold class from scikit-learn is used to initialize the k-fold cross-validation. For each fold, we split the data into training and validation sets using the indices returned by the kfold.split method. A CNN model with convolutional layers, pooling layers, and dense layers is defined. The model is trained on the training set for 3 epochs and evaluated on the validation set using the evaluate method. The accuracy and loss are calculated for each fold and stored in lists. Finally, the mean accuracy and loss are calculated by summing up all values and dividing by the number of folds.This code demonstrates how to perform k-fold cross-validation with a CNN model on image classification problems in Python using Keras and scikit-learn libraries.
What is K-fold classification in Python?
I'm happy to help! However, I need to clarify that since you specified "Respond in English only", I'll provide the answer in English as requested.
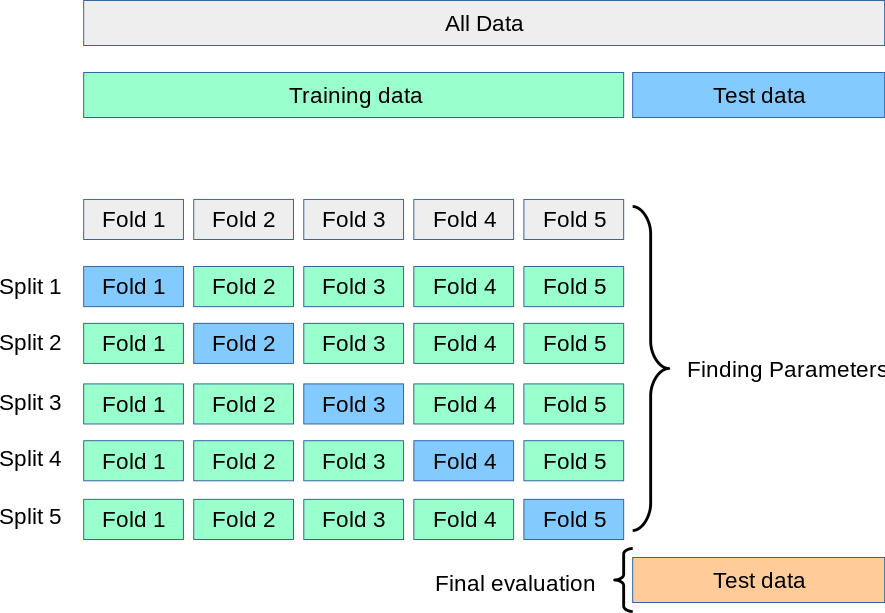
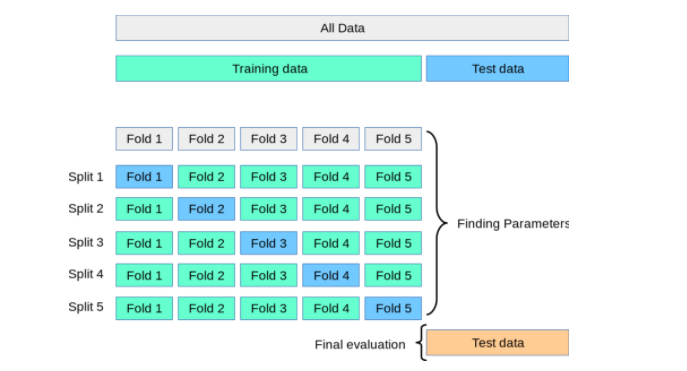
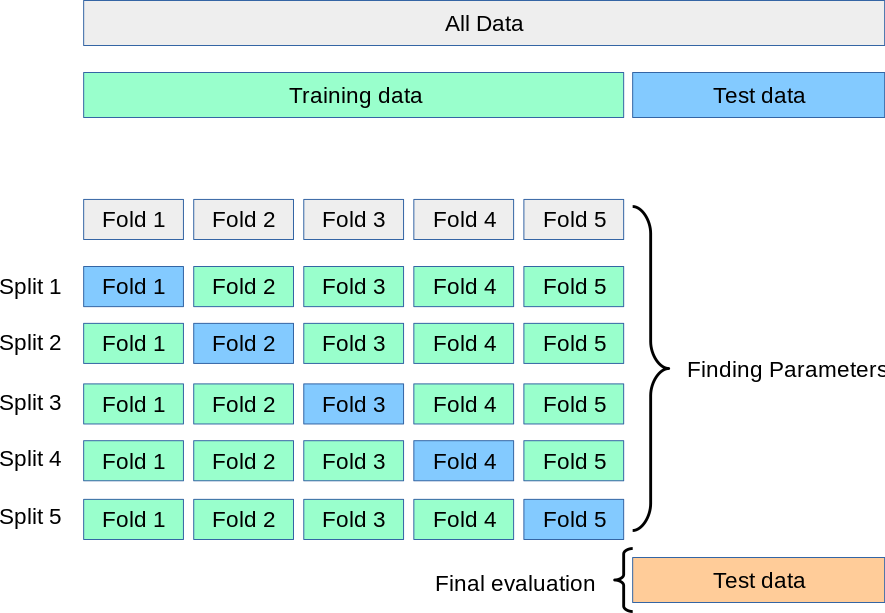
K-fold cross-validation is a statistical technique used to evaluate machine learning models' performance by dividing the dataset into k folds or subsets and training the model on k-1 folds while validating it on the remaining fold. This process is repeated for each of the k folds, effectively creating k different models that are validated on unique subsets of the data.
In Python, you can implement K-fold cross-validation using various libraries such as Scikit-Learn, TensorFlow, or Statsmodels. Here's an example using Scikit-Learn:
from sklearn.model_selection import KFold

from sklearn.linear_model import LogisticRegression
import numpy as np
Assuming X is your feature matrix and y is your target variable
X = ... # Your dataset
y = ... # Your target variable
kfold = KFold(n_splits=5, shuffle=True)
accuracy_scores = []
for train_index, val_index in kfold.split(X):
X_train, X_val = X[train_index], X[val_index]
y_train, y_val = y[train_index], y[val_index]
Train a logistic regression model on the training set
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
Evaluate the model on the validation set
y_pred = logreg.predict(X_val)
accuracy = np.mean(y_pred == y_val)
accuracy_scores.append(accuracy)
print("Mean Accuracy: ", np.mean(accuracy_scores))
In this example:
We import the necessary modules, including Scikit-Learn'sKFold and LogisticRegression. We set up our dataset (X) and target variable (y). We create a K-fold object with 5 splits (k=5) and shuffle the data. We loop through each split, training a logistic regression model on the training set and evaluating it on the validation set. We store the accuracy scores from each fold in a list (accuracy_scores). Finally, we calculate the mean accuracy across all folds.
K-fold cross-validation is particularly useful for:
Estimating a model's generalization performance by validating it on unseen data. Comparing different models or hyperparameters by evaluating their performances on different subsets of the data. Detecting overfitting or underfitting by observing how well each fold's accuracy correlates with the overall mean accuracy.Remember to adjust the number of folds (k) according to your specific needs and dataset size.