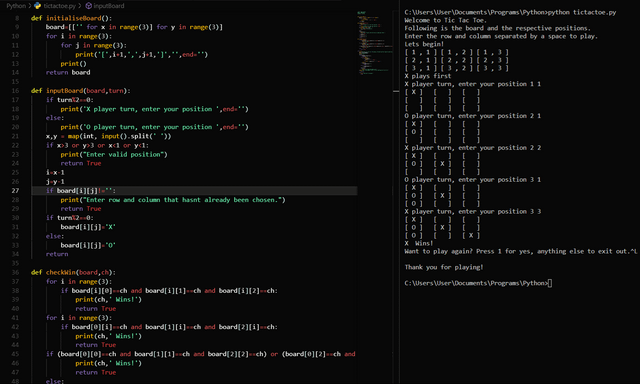
Python gensim tutorial
Python gensim tutorial

I'd be happy to provide a detailed tutorial on using Gensim for natural language processing (NLP) tasks in Python!
What is Gensim?

Gensim (Generative Syntax-based Information Model) is an open-source Python library for topic modeling and document similarity analysis. It allows you to perform various NLP tasks, such as:
Topic Modeling: Identify the underlying topics or themes in a large corpus of text data. Document Similarity Analysis: Measure the similarity between two documents based on their content.Prerequisites
Before we dive into the tutorial, make sure you have Python 3.x installed and familiar with basic Python concepts.
Step 1: Installing Gensim
To install Gensim, use pip:
pip install gensim
Step 2: Preparing the Data
For this tutorial, we'll use a sample corpus of text files (e.g., .txt or .md) stored in a directory. Create a new directory for your project and add your text files to it.
Next, create a Python script (e.g., gensim_tutorial.py) with the following code:
import osfrom gensim import corpora
Set the path to your corpus directorycorpus_dir = 'path/to/your/corpus/directory'
Create a list of file namesfile_names = [os.path.join(corpus_dir, f) for f in os.listdir(corpus_dir)]
print("Files found:", len(file_names))
Step 3: Preprocessing the Data
Modify the script to preprocess your text data. For example:
Tokenization: Split each text file into individual words (tokens). Stopword removal: Remove common stopwords like "the", "and", etc. Stemming or Lemmatizing: Reduce words to their base form.Here's an updated script:
import osfrom gensim import corpora, utils
from nltk.tokenize import word_tokenize
Set the path to your corpus directorycorpus_dir = 'path/to/your/corpus/directory'
Create a list of file namesfile_names = [os.path.join(corpus_dir, f) for f in os.listdir(corpus_dir)]
print("Files found:", len(file_names))
Initialize an empty list to store preprocessed documentsdocs = []
for filename in file_names:
with open(filename, 'r') as file:
text = file.read()
Tokenize the texttokens = word_tokenize(text.lower())
Remove stop words and punctuationtokens = [t for t in tokens if not utils.is_stop(t) and not t.isalpha()]
Add the preprocessed document to the listdocs.append(tokens)
print("Preprocessed documents:", len(docs))
Step 4: Creating a Corpus
Now that you have your preprocessed data, create a Gensim corpus object:
from gensim import corpora Create a dictionary from the preprocessed documentsdict = corpora.Dictionary(docs)
Convert the list of documents into a Gensim corpuscorpus = [dict.doc2bow(doc) for doc in docs]
Step 5: Training a Topic Model
Choose a topic modeling algorithm (e.g., Latent Dirichlet Allocation (LDA)) and train it on your corpus:
from gensim.models import TfidfModel, LdaModel Create a TF-IDF model to transform the datatfidf_model = TfidfModel(corpus)
Convert the corpus into TF-IDF representationcorpus_tfidf = [tfidf_model[doc] for doc in corpus]
Train an LDA topic model on the TF-IDF corpuslda_model = LdaModel(corpus_tfidf, id2word=dict, passes=15)
Step 6: Analyzing the Results
Use the trained topic model to:
Identify topics: Get a list of the top words for each topic. Compute document similarities: Calculate the similarity between two documents based on their topic distributions.Here's an example code snippet:
# Get the top words for each topictopic_words = [(topic_id, [word for word, score in topics[topic_id]] )
for topic_id in range(lda_model.num_topics)]
print("Topic words:", topic_words)
Compute document similaritiesdocument_similarities = []
for i in range(len(corpus)):
for j in range(i + 1, len(corpus)):
similarity = lda_model.doc_similarity(corpus[i], corpus[j])
document_similarities.append((i, j, similarity))
print("Document similarities:", document_similarities)
That's it! This tutorial has covered the basic steps of using Gensim for topic modeling and document similarity analysis. You can now explore more advanced topics (pun intended!), such as:
Topic evolution: Track changes in topic distributions over time. Document clustering: Group documents based on their topic similarities.Remember to keep your data well-preprocessed, and you'll be amazed at the insights Gensim can uncover!
Python gensim examples
Here are some Python Gensim examples that demonstrate how to work with word embeddings:

Example 1: Word Embeddings from Scratch
This example shows how to train a word2vec model from scratch using the Gensim library.
from gensim.models import Word2Vec
import nltk
Load your dataset (e.g., sentences)
sentences = ...
Set parameters for training
min_count=5, size=100)
Train the model
word2vec_model = Word2Vec(sentences, min_count=min_count, size=size)
Save the model to disk
word2vec_model.save('w2v.model')
Example 2: Loading a Pre-Trained Word Embedding Model
This example shows how to load a pre-trained word2vec model using the Gensim library.
from gensim.models import Word2Vec
Load the pre-trained word2vec model
model = Word2Vec.load('w2v.model')
Use the loaded model for further analysis (e.g., similarity, analogy)
...
Example 3: Similarity Analysis
This example shows how to perform similarity analysis using a trained word2vec model.
from gensim.models import Word2Vec
Load the pre-trained word2vec model
model = Word2Vec.load('w2v.model')
Calculate the similarity between two words
word1 = 'apple'
word2 = 'banana'
similarity = model.wv.similarity(word1, word2)
print(f"Similarity between '{word1}' and '{word2}': {similarity}")
Example 4: Analogy Analysis
This example shows how to perform analogy analysis using a trained word2vec model.
from gensim.models import Word2Vec
Load the pre-trained word2vec model
model = Word2Vec.load('w2v.model')
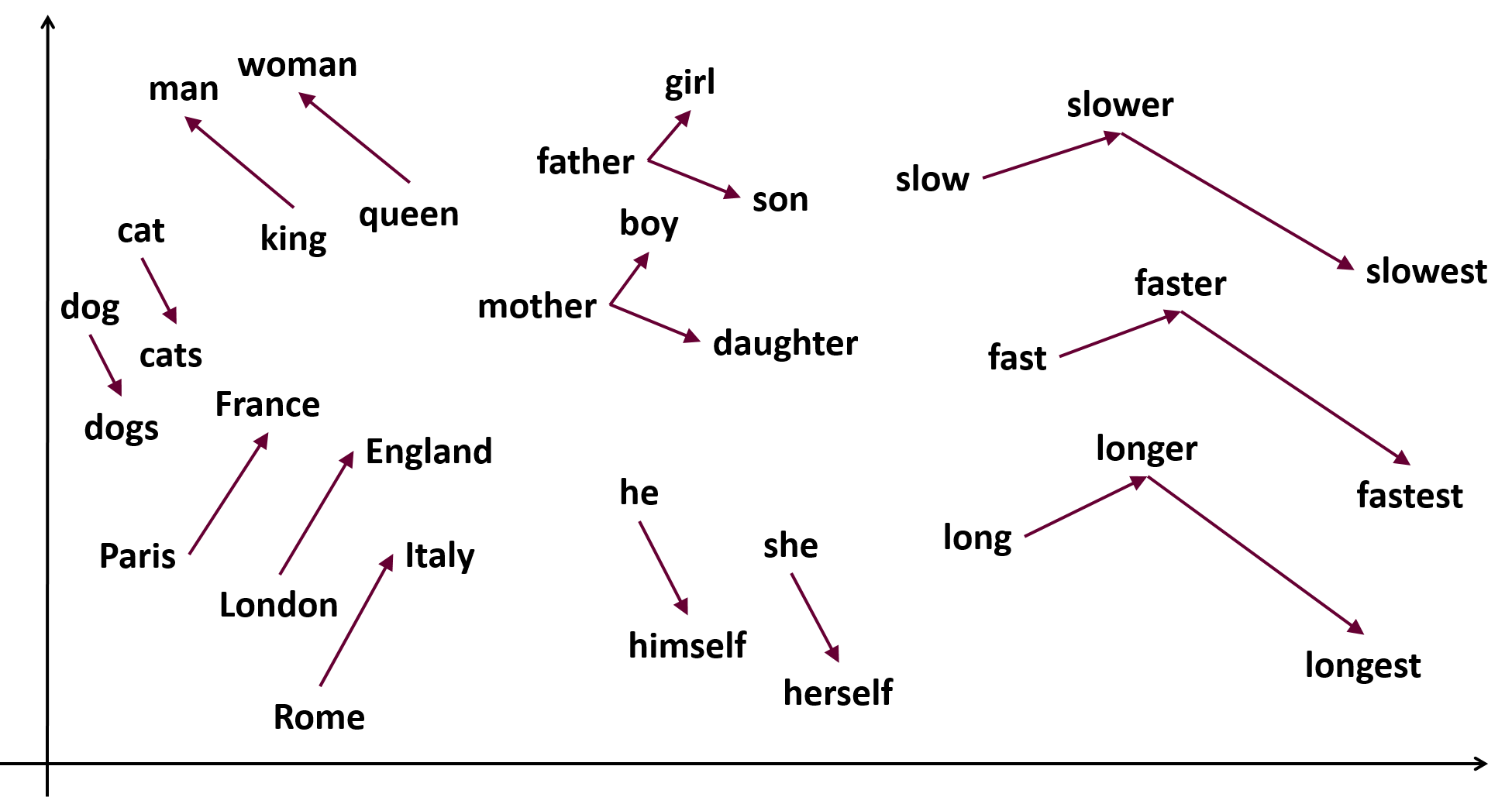
Define the analogy (e.g., king - man + woman)
analogy = 'king' - 'man' + 'woman'
Get the most similar words for each part of the analogy
word1_similar_words = model.wv.most_similar(positive=[analogy[0]], negative=[analogy[2]])
word2_similar_words = model.wv.most_similar(positive=[analogy[1]], negative=[analogy[2]])
Print the results
print(f"Analogy: {analogy}")
print(f"Most similar words for '{analogy[0]}' and '{analogy[2]}': {word1_similar_words} & {word2_similar_words}")
These are just a few examples of how you can use Gensim to work with word embeddings in Python.