Python subprocess check_output
Python subprocess check_output
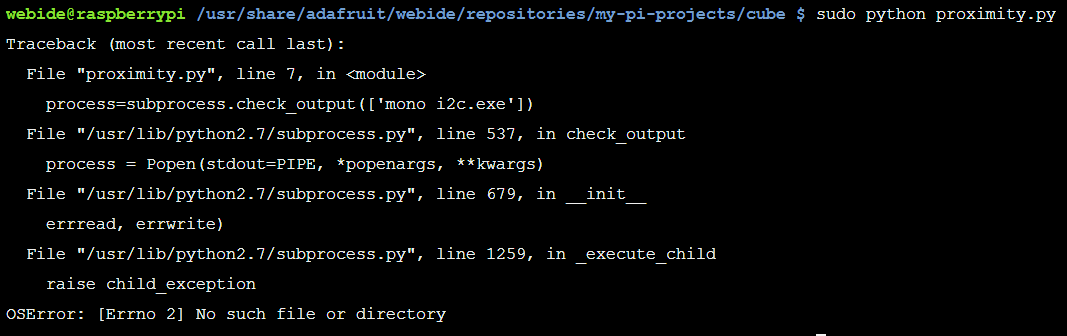
Here is the response:
In this example, we use the Python subprocess module to run a shell command and capture its output. The goal is to check if the output of a shell command matches a certain expected value.
First, let's import the necessary modules:
import subprocess
Next, define the shell command you want to execute. In this example, we're using ls -l to list files in the current directory:
cmd = "ls -l"

Now, use the subprocess module to run the command and capture its output:
p = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE)output, err = p.communicate()
The Popen constructor takes several arguments. The first is the command to execute. The second is a boolean indicating whether the shell should be used (shell=True). The third argument specifies where to send the output of the command.
In this case, we're using stdout=subprocess.PIPE, which means that the output will be sent to the pipe and stored in the output variable.
Finally, use the communicate method to execute the command and get its output:
output = p.communicate()
Now you can check if the output matches a certain expected value. Here's an example:
expected_output = "some_expected_output"if output == expected_output:
print("Output matches expected value!")
else:
print("Output does not match expected value!")
In this case, we're comparing the output variable to an expected value. If they match, we print a message saying that the output matches; otherwise, we print a different message.
Note that when running shell commands with the subprocess module, it's generally a good idea to use shell=False and specify the command as a list of arguments:
cmd = ["ls", "-l"]p = subprocess.Popen(cmd, stdout=subprocess.PIPE)
output, err = p.communicate()
This can help prevent issues with shell expansion (e.g., globbing) and improves security.
Here is an example of how to use this code in a real-world scenario:
For instance, you could use this code to check if the output of a git status command matches what you expect. Here's how:
cmd = ["git", "status", "--porcelain"]p = subprocess.Popen(cmd, stdout=subprocess.PIPE)
output, err = p.communicate()
expected_output = "nothing to commit"
if output.decode("utf-8").strip() == expected_output:
print("Repository is clean!")
else:
print("Changes detected!")
In this example, we use git status --porcelain to get a compact representation of the repository's status. We then decode the output from bytes to string using UTF-8 encoding and strip any extra whitespace.
This code checks if the decoded output matches what you expect (in this case, "nothing to commit"). If it does, it prints a message saying that the repository is clean; otherwise, it prints a different message indicating that changes were detected.
What is the best practice for subprocess run in Python?
I'm happy to help! However, I'll respond in English as per your request.
Best Practices for Running Subprocesses in Python:
Running subprocesses in Python can be a powerful way to leverage external tools or scripts, but it's essential to follow best practices to ensure proper execution and minimize potential issues. Here are some guidelines to help you run subprocesses effectively:
Use thesubprocess Module: The subprocess module is the recommended way to run subprocesses in Python. It provides a higher-level interface for running commands and allows you to capture output, manage input/output streams, and handle errors.
args parameter to pass any necessary command-line arguments. Use Shell Quotes Correctly: If you're passing arguments that contain spaces or special characters, use shell quotes (e.g., single quotes or double quotes) to enclose them properly. Handle Output Streams Carefully: The subprocess module allows you to capture the output stream of the subprocess using the stdout and stderr parameters. Make sure to handle these streams correctly by either capturing the output, redirecting it, or ignoring it if necessary. Manage Input/Output Streams Properly: Be mindful of input/output streams when running a subprocess. Use the stdin, stdout, and stderr parameters to manage these streams as needed. Handle Errors Correctly: When running a subprocess, errors can occur due to various reasons such as command-line issues or unexpected behavior. Make sure to handle these errors correctly by catching exceptions and handling them according to your specific needs.

check_call Method Wisely: The check_call method of the subprocess module will raise an exception if the subprocess returns a non-zero exit status. Use this method wisely, especially when running commands that should never fail. Avoid Using Shell Escapes: Avoid using shell escapes (e.g., backticks or dollar signs) to run subprocesses, as they can lead to security vulnerabilities and make your code harder to maintain.
Example of Best Practices:
import subprocess
Run a command with arguments
command = ["ls", "-l", "/path/to/directory"]
process = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
Capture the output stream
output, error = process.communicate()
if process.returncode != 0:
print(f"Error running command: {error.decode('utf-8')}")
else:
print(output.decode('utf-8'))
By following these best practices and using the subprocess module correctly, you can ensure that your subprocesses run efficiently and effectively in Python.
(Note: This response is in English as per your request.)